
10/5 記事の説明を大幅に更新しました。
アップデート v0.4.2およびv0.4.3(10/5)
- アップデート機構を修正
- 比較タブの『verをENに合わせる』で本文が二重エスケープされる不具合を修正
- JA側に既存がある場合は raw を保ったまま version 属性のみ置換/追加/削除
- ツールチップ挿入機能追加
- 自動アップデートの汎用化
過去のアップデートログ:
アップデート v0.4.1(9/17)
- UI/CSS 安定化
- 自動アップデートの汎用化
アップデート v0.4.0(9/17)
- アップデート機構の追加
- 自動チェック: 起動時にGitHub最新を確認。最新版なら「最新です(現在 x.y.z)」、更新ありならバナー表示
- 手動チェック: ヘッダーに「更新確認」ボタンを追加
- 比較(XML差分)の実用度アップ
- 差異の拡充: 「version差異」「本文差異+version差異」を新設
- ソート: 状態ヘッダーで並び替え(優先: version差異系 → 一致 → 欠落系 → 本文差異)
- 表示最適化: ver一致時は「[ver一致]」、差異時は⚠で警告(マウスオーバーに説明)
- JAなしコピー: 原文XMLをversion付きでコピー、欠落時は備考のverENから補完
- 整合ボタン: 「verをENに合わせる」でJA側versionをENに一括反映
- ダークテーマ: グレー基調で見やすく、Prismのtext-shadowを無効化しハイライト改善
- 検索: 日本語/英語対応、空白区切りAND、重複除外の説明をツールチップ化
アップデートv0.3.2(9/15)
- 比較機能でversion表記に対応していなかった問題を解決
アップデートv0.3.1(9/10)
- 3カラム表示: 原文(XML)/ 状態(例: JAなし)/ 備考(verEN, verJA, JAプレビュー)で一覧性アップ
- XMLハイライト: Prismを使ってタグや属性が読み取りやすい(折り返し表示で横スクロール不要)
- 列境界線&等幅フォント: ラインがそろい、差分の把握が速い
- JA欠落だけコピー: 「JAなしの行」だけをワンクリでクリップボードへ(改行は1つに正規化)
- EN補完行の強調: 「JA欠落をENで補完」後、補完された行が薄い青で自動ハイライト
- 全幅切替ボタン: 画面幅をワイドにして一気にレビュー。状態は自動保存
はじめに
BG3 の MOD を日本語化していると、
- 統一された訳を作りづらい(固有名詞がそもそも多すぎる)
- 固有名詞をひとつずつ探すのに手間がかかりすぎる
- EN/JA の
.loca.xmlを突き合わせて辞書化するのが面倒
この辺を一気に解決するために、ローカル専用の翻訳補助ツールを作りました。
導入とインストール
上記のリリースページから、ソースコードをダウンロードしてください。
Source code(zip)というやつです。
① Python の準備
- 必要バージョン:3.11以上(3.12や3.13でもOK)
→ Pythonっていうプログラムを動かすための“エンジン”みたいなもの。これがないと始まらない。
- Windows の人は「
Add Python to PATH」にチェックを入れてインストール。- これを忘れると、次の手順がうまくいかないので注意!
② 仮想環境を作る
ツールを入れたフォルダの中で コマンド操作をする。
(※コマンドプロンプトでもPowerShellでもOK。mac/Linuxはターミナル)
Windows の場合
- ツールを展開したフォルダを右クリック → 「ターミナルで開く」
- こんなコマンドを順に入力(コピペでOK):
python -m venv .venv
.venv\Scripts\Activate.ps1
pip install --upgrade pip
pip install -r requirements.txtmacOS / Linux の場合
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txtこれで「必要な部品(ライブラリ)」が揃う。
※もしエラーで lxml が入らないときは:
pip install --only-binary=:all: lxml==5.2.2または requirements.txt の lxml の行を消して再トライ。
③ サーバーを起動する
いよいよツールを動かす!
Windows の場合
- フォルダにある
run_dev.batをダブルクリック(開発用)
またはrun_prod.bat(本番用) - どっちでも動くから、どっちでもいいです。
macOS / Linux の場合
ターミナルで:
uvicorn api.main:app --reload👉 起動すると自動でブラウザが開いて、
http://127.0.0.1:8000/ui/ が表示される。
これが翻訳DBの操作画面です。
対訳データーベースを取り込んであるので、そのまま準備なしで使えます。
このツールは MODを自動翻訳するツールではありません。
翻訳そのものは Gemini などの AI 翻訳サービスに任せる想定です。
ただし、AI翻訳には大きな弱点があります。
それは 固有名詞や専門用語がバラついて統一されない こと。
キャラ名や呪文名、ゲーム特有の用語が毎回違う訳にされてしまうのです。
補助としてどのように使うか?
やることはシンプルで、
固有名詞やよく使われる単語を「対訳リスト(TSV)」として抽出・管理すること です。
- MODや公式訳ファイルをインポートしてDB化
- よく出てくる単語・固有名詞を検索・照会
- 対訳TSV(英語→日本語) として一括エクスポート
- 翻訳依頼時に、このTSVを「翻訳指示」と一緒にAIへ渡す
こうすることで、AI翻訳のスピードは活かしつつ、
固有名詞の精度・統一性を最大化 できます。
イメージで言うと…
AI翻訳は速いけど雑な通訳さん。
名前や専門用語をしょっちゅう間違える。
そこでこのツールが “カンペ(用語集)” を用意する。
「この人は“田中”、この魔法は“ファイアボール”って呼んで!」とメモを渡す感じです。
結果、
- 速さはAI任せ
- 精度は辞書でカバー
という翻訳環境が完成します。
MOD日本語化ワークフロー(AI+Translation DB Tool)
1. AI環境の準備
翻訳に使うAIは何でもよいですが、おすすめは Google AI Studio
理由はシンプル:
- 無料で使える
- ほぼ無制限に大量の作業を投げられる
- 長文データも処理できる
つまり「MOD翻訳のような大規模作業」に最適です。
2. MODの英語版言語ファイルを用意
翻訳元となるのは、MODに含まれている 英語版の言語ファイル。
拡張子はだいたい .loca.xml とかで、
ゲーム内のセリフやUIテキストが全部ここに入っています。
bg3-modders-multitoolなどで.pak解凍して、Translationフォルダから引っ張ってこよう!
たいていEnglish/〇〇.loca.xmlみたいな感じで入ってる。
locaついてなくても言語ファイルなので、翻訳していこう。
3. 固有名詞リストをAIに作らせる
その 英語版xmlファイルの中身を丸ごとコピーしてAIに貼り付け、こう指示します:
# Baldur's Gate 3 名称抽出ルール
## 1. 目的
Baldur's Gate 3 のゲームデータ(XML、テキスト等)から、固有名詞・ゲーム内識別子・特有キーワードを抽出し、
ゲーム内名称リストやローカライズ参照表の作成に利用する。
---
## 2. 抽出対象
### 固有名詞・固有名称
スキル名、アイテム名、クラス名、キャラクター名、召喚名、能力名など。
### ゲーム内識別子
<LSTag> タグの Tooltip 属性値を対象とする。
(例: <LSTag Tooltip="SavingThrow"> → Tooltip="SavingThrow")
### 特定キーワード
文中で名称的に使われる BG3 特有の属性や概念(例: astral, cosmic, necrotic, psychic, frost)。
大文字・小文字を問わず抽出する。
### 特例キーワード
UI用語の Main hand, Off hand は、データ内に存在しなくても必ず抽出結果に含める。
---
## 3. 抽出・処理ルール
### 複合名称の扱い
複数単語からなる名称は、「完全名称」と「構成単語」を両方抽出する。
例: Chadrick the Druid → Chadrick the Druid, Chadrick, Druid
### 単語分解ルール
名称は以下を区切り文字として分割し、「分解(Decomposed)」リストに出力する。
CamelCase、コロン (:)、スラッシュ (/)、ハイフン (-)、アンダースコア (_)、空白。
### 正規化
- Main hand, Off hand は表記ゆれを許さず統一(半角スペース1つ)。
- 単数・複数形は単数形に統一(例: Wounds → Wound)。
- 英字は抽出時点の表記を維持(例: SavingThrow はそのまま)。
### データソースの扱い
- XML: <content> タグ本文および属性値(Tooltip)を解析対象とする。
HTMLエスケープ文字はデコードして扱う。
- テキスト: 同様の基準で名称・キーワードを解析。
---
## 4. 出力仕様
### 出力構成
出力は以下の3セクションをこの順で並べる。各セクションの間に1行の空行を挟む。
1. 固有名詞・名称
2. Tooltip / ID
3. 分解(Decomposed)
### 出力フォーマット
- 各項目は1行ごとに出力する。
- Tooltipは Tooltip="..." の形式でそのまま出力する。
- 説明文やコメントは含めない。
### 常時出力語
抽出対象に存在しなくても、必ず最下部に以下を出力する。
Main hand
Off hand
---
## 5. 対話スタイル
### 基本応答
結果は要求されたテキストリストのみを出力する。
説明やコメントは付けない。
### 例外
抽出動作やルールの確認が必要な場合に限り、
簡潔な日本語で補足や質問を行う。
AIはキャラ名、呪文名、スキル、能力値などを抽出し、固有名詞リスト を返してくれます。
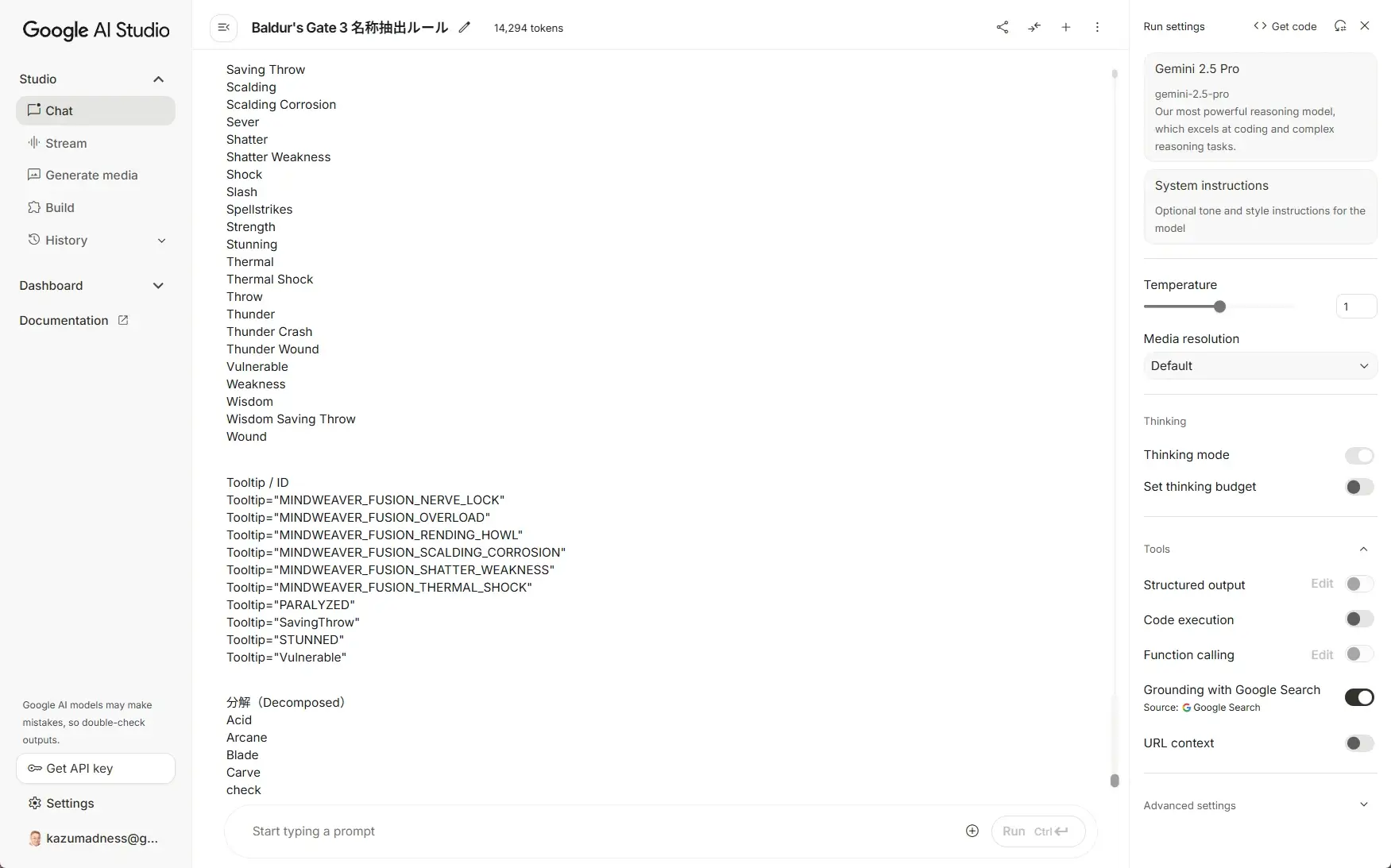
4. リストをTranslation DB Toolで照会
- 抽出したリストをコピー
- Translation DB Tool の「照会」タブにペースト
- 「照会」ボタンを押す
すると、リストの単語に対応する 既存の日本語訳(公式訳や過去訳) があれば一覧表示されます。
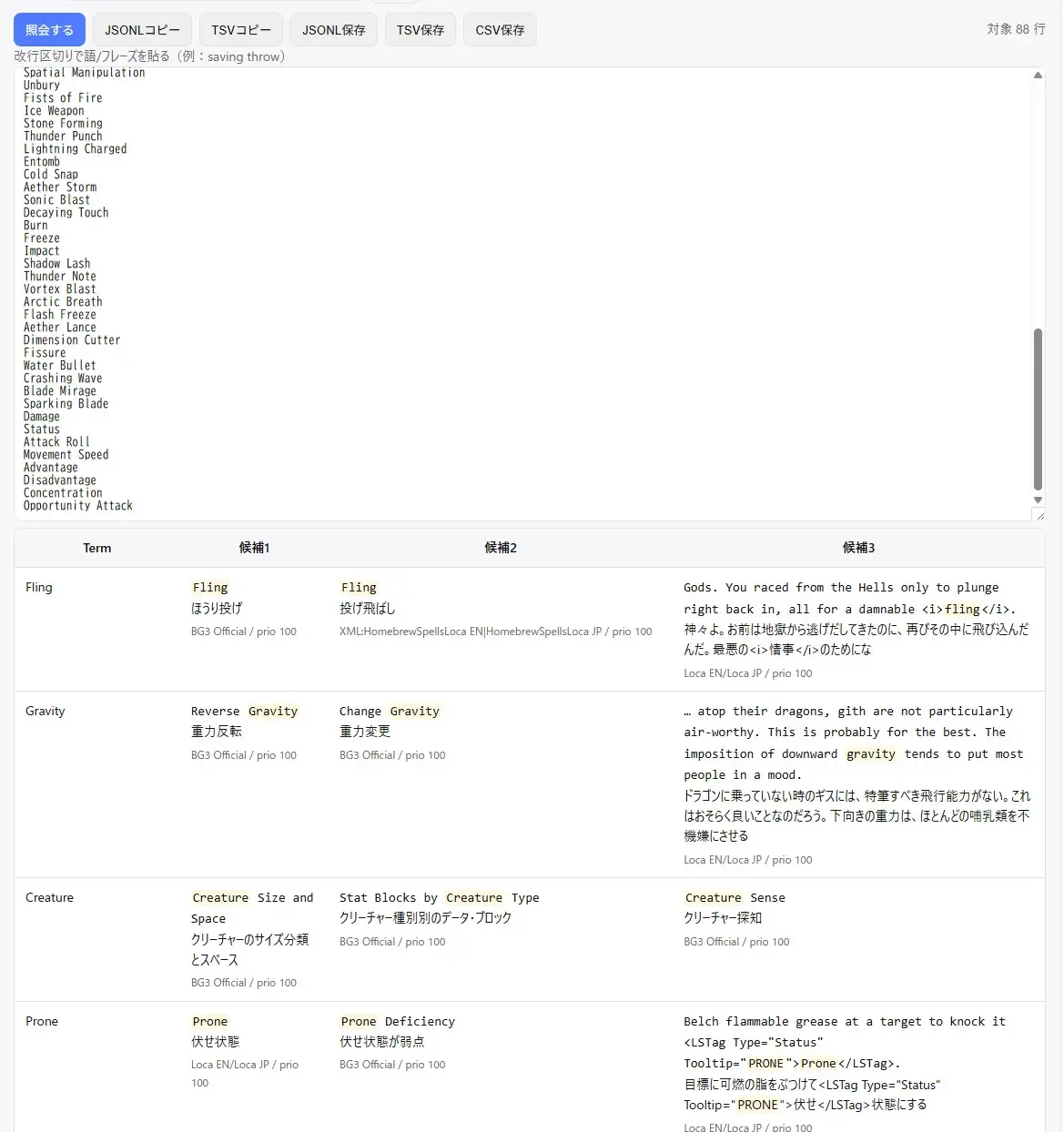
デフォルトでは候補が3つまで表示されます。とりあえず3つくらい候補を投げておけば、翻訳が安定するからです。
5. 対訳TSVを作る
照会結果はワンクリックで TSVコピー できます。
さらに「プロンプトタブ」で設定した 翻訳指示文(カンペ)」 が自動で先頭に差し込まれます。
つまり出力されるのは:
- 翻訳指示文(プロンプト)
- 固有名詞対訳リスト(TSV)
という AIに渡すための翻訳セット になります。
プロンプトは自分で好きなように編集してください。
私がよく使うプロンプトを置いておきます。ちょっと指示が硬すぎて使いづらいときもありますが。
# 翻訳作業・絶対遵守ガイドライン
## 絶対ルール
XML構造を完全に保持すること。
XML宣言、タグ、属性、改行などを一切変更してはいけません。
翻訳対象は `<content>` タグ内テキストのみとする。
---
## 用語と資料遵守
用語はTSVや公式訳を最優先とする。
固有名詞・スキル名・アイテム名は、必ず資料にある訳語を使用すること。
例:
`Quick Step → 素早い足取り`(「クイックステップ」は不可)
---
## ツールチップ
資料に明示されたもののみ残す。
存在しないツールチップを独自に追加してはいけない。
---
## 翻訳スタイル
常体(〜だ/〜である)を基本とする。
直訳ではなく、文学的で格調高い響きを目指す。
必要に応じて体言止めを使用してもよい。
「あなた」という二人称は避け、可能な限り省略、または「自身」「着用者」とする。
---
## 出力形式
出力はXMLコードのみ。
前置き・後書き・注釈は禁止。
必ず ```xml コードブロック``` で囲むこと。
`<LSTag>` などのゲーム独自タグはそのまま保持する。
`[n]` のプレースホルダも原文のまま保持する。
---
## 自己確認チェックリスト
構造を保持できているか。
翻訳範囲は `<content>` のみか。
用語・ツールチップは資料に忠実か。
文体は常体で統一されているか。
出力に余計なテキストが混ざっていないか。
---
このルールは翻訳作業における基本原則であり、
一つでも逸脱すれば全体の信頼性が損なわれる。
構造の厳密さと文体の品格を常に両立させること。うまくいかない場合は、プロンプトを調整してください。その辺はご自由に試行錯誤してください。
6. AIに本番翻訳させる
作成した プロンプト+TSV+原文 をAIに渡して翻訳開始。
AIは用語リストに従い、固有名詞や専門用語を統一して翻訳してくれます。
7. 翻訳を別会話でチェック
翻訳が出揃ったら、AIに校正させるのも効果的。
ただし会話は分けるのがコツ。
- 会話1:固有名詞抽出(リスト作成)
- 会話2:翻訳(TSV+プロンプトで仮翻訳)
- 会話3:チェックし本翻訳(原文+翻訳を突き合わせ、不自然な日本語や誤訳を指摘させる)
こうすることで、誤訳や変な日本語をかなり減らせます。
8. 会話は定期的に新しくする
Geminiは、一つの会話でのやり取りが長くなるほど(トークン数が増えるほど)、初期の指示を忘れてしまう傾向があります。そのため、特に複雑な翻訳作業などを同じ会話で続けると、最初は精度が高くても、回数を重ねるにつれて翻訳漏れなどのエラーが増えていきます。
なぜ会話が長くなると指示を忘れるのか
AIが一度に処理できる情報の量には、「コンテキストウィンドウ」と呼ばれる上限があります。これは、AIが会話の文脈を記憶しておくための「作業机の広さ」のようなものです。
会話が長くなり、やり取りされる情報(トークン)の総量がこの上限を超えると、古い情報から順に押し出されてしまいます。その結果、会話の初期に与えられた細かい指示や前提条件をAIが「忘れて」しまい、応答の精度が低下したり、指示の抜け漏れが発生したりします。
特に、以下のような場合にこの現象は顕著になります。
- 複雑な指示や複数のルールがある場合
- 翻訳作業のように、守るべきルールが多いタスクでは、一部が記憶から抜け落ちやすくなります。
- 長文のデータを扱う場合
長い文章の要約や分析をさせると、文章の冒頭部分の内容が要約から抜け落ちることがあります。 - 多数のやり取りを重ねた場合
何十回も対話を続けると、初期の文脈が失われ、話が噛み合わなくなることがあります。
なのであんまり無理をさせずに、諦めてどんどん新たな会話を始めてやり直していったほうがよいです。
翻訳作業補助ツールの機能説明
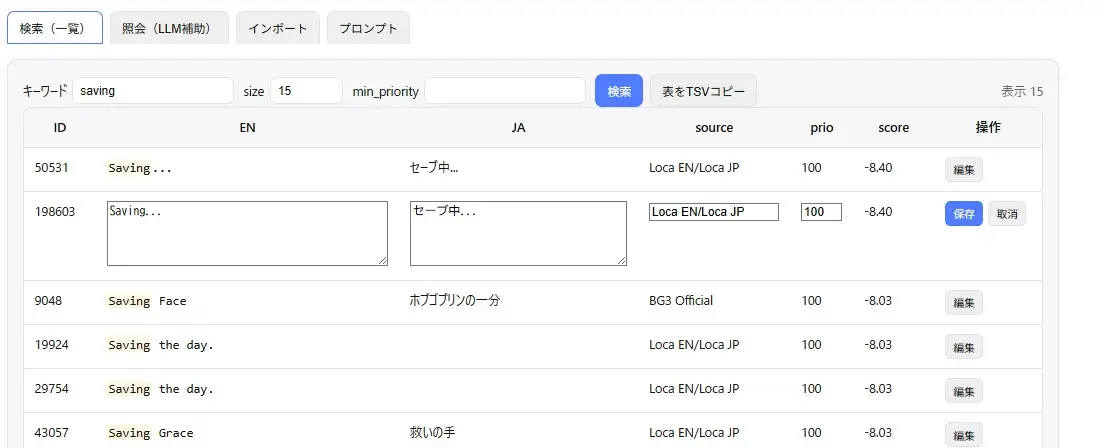
検索機能
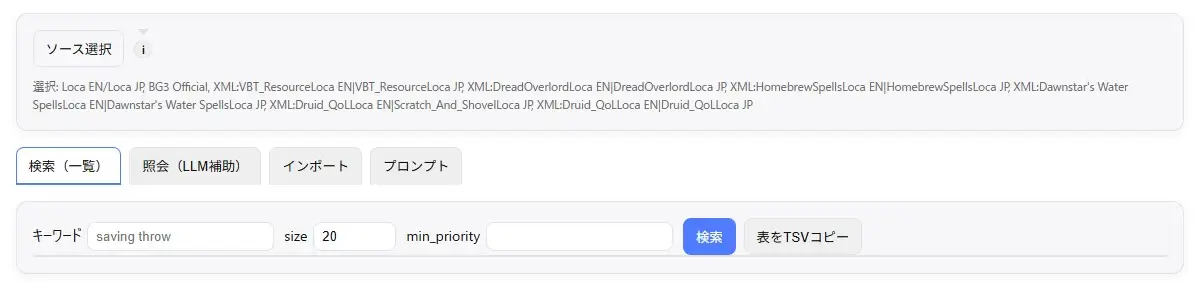
シンプルに英文の公式訳を探す際に使います。
sizeで候補数を増減できます。
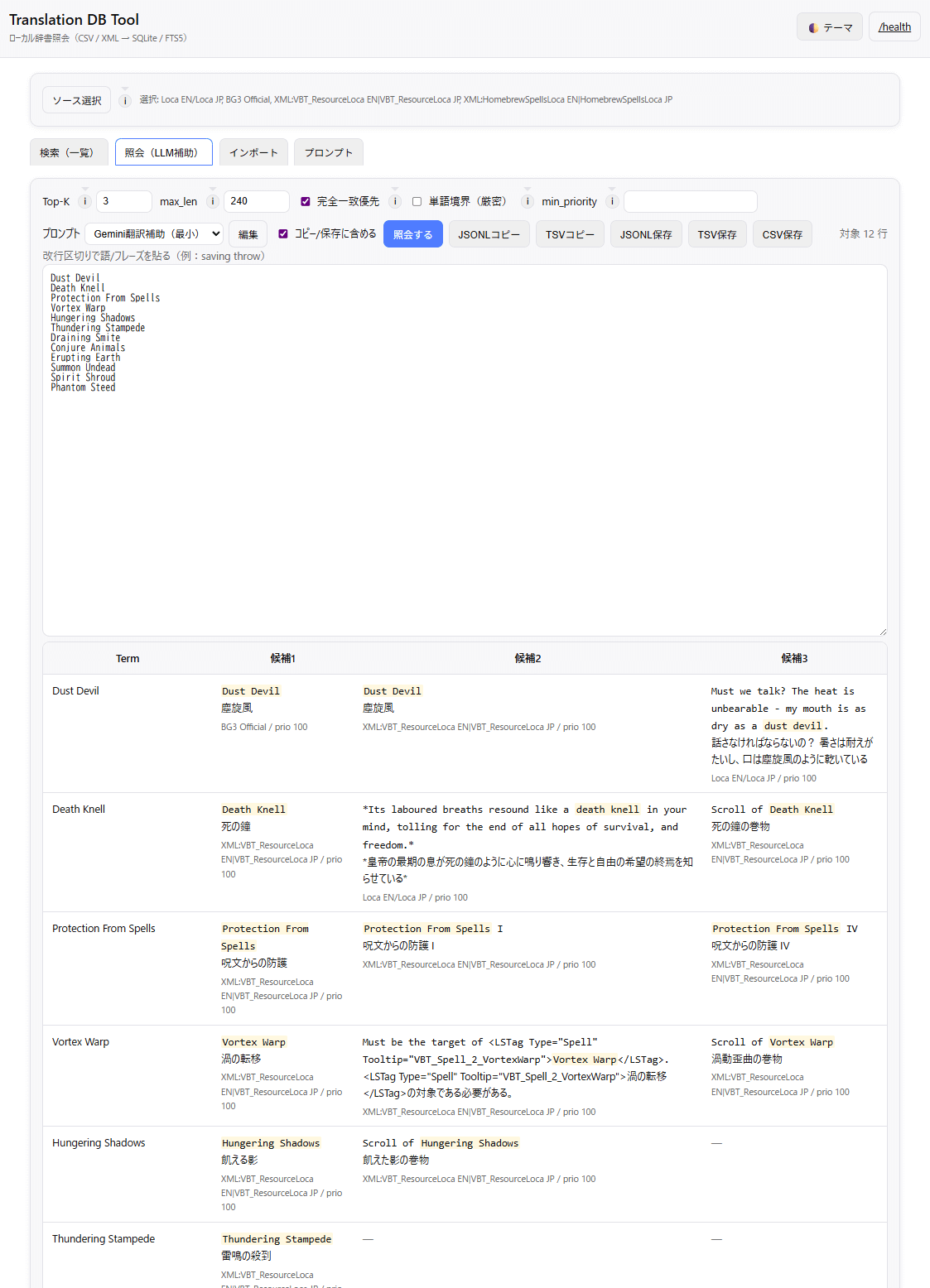
照会(LLM補助)
AI翻訳の最大の弱点(固有名詞・専門用語のブレ)を抑え、訳語を統一するための「用語カンペ(対訳TSV)」を素早く作る機能です。AIの速さは活かしつつ、辞書(既存訳・公式訳)で精度と一貫性を担保します。
JSONL/TSV/CSV(必要なら先頭にプロンプト文を自動挿入)。そのままAIに渡せる形に整えます。
いつ使う?
- 固有名詞リストをAIで抽出した“直後”(本番翻訳に入る前)
- MOD更新時の「用語ゆれ」再固定
- 公式訳との照合・比較の後、用語最終確認として
- 校正前の「用語統一チェック」用カンペ作成
使い方(はじめてでもこれだけでOK)
ソース選択で対象データを選ぶ- タブで
照会(LLM補助)を開く - 語リスト欄に「1行=1語/フレーズ」で貼り付け
Top-K(2〜4推奨)/完全一致優先(ON推奨)/min_priority(60~120推奨)- プロンプトを選び、必要なら
コピー/保存に含めるをON 照会する→ 候補(EN/JA/SRC/PRIO)が出るJSONLコピー/TSVコピーまたは保存で出力- 出力(プロンプト+対訳)をAIに渡して翻訳開始
データベースへの翻訳インポート機能

この機能は、英語と日本語の.xmlをペアで読み込んで、辞書を増やすために使います。英語と日本語の.xmlをDBに取り込み、UUID(contentuid)で比較し対にします。これで検索・照会・比較に使える辞書が増えます。
作成した翻訳ファイル(日本語/英語)をそれぞれ全く同じ行数、同じUUIDで作成していることが前提ですが、訳の資料として既存データーベースへ追加できます。
一度翻訳したMODがアップデートされた場合などに、固有名詞がブレることを防ぐことができます。
手順
- インポートタブで、
英語版のxmlと日本語版のxmlを選ぶ(ソース名は自動入力。直してもOK) priorityを決める(数字が小さいほど「強い訳」)strict(IDが完全一致かチェック)やreplace_src(同じソース名を上書き)を必要に応じてON/OFFXMLインポートを押す → 終わるとすぐ検索や照会に使えます- 失敗したら、UTF-8か、XMLの形(タグ)を確認
- 上書きしたくない時は、
replace_srcをOFFにするか、ソース名を変えます
比較(xml差分)機能
比較(XML差分)機能とは
英語版XMLと日本語版XMLを突き合わせて、同じ <content>(UUID)ごとに「どこが翻訳済みで、どこが未訳か」「本文やバージョンに変更があるか」を自動判定します。
MOD更新時に「新しいテキストが追加されたか」「既存の翻訳に影響があるか」を即座に確認できます。
主な判定結果
- 一致:両方にあり、内容が完全に同じ(翻訳済み・変更なし)
- JAなし:英語にはあるが日本語にない(新規追加・未翻訳)
- ENなし:日本語にはあるが英語にない(削除・改名などの可能性)
- 本文差異:UUIDは同じだが本文が異なる(テキスト変更あり)
- version差異:本文は同じだがversion属性が異なる(軽微な更新や差分確認用)
- 本文差異&version差異:UUIDは同じだが本文とversion属性が異なる(テキストが完全に更新されている)
こんな時に便利
- MODの新バージョンがリリースされた
- 「翻訳ファイルも更新が必要?それとも前のバージョンのまま使える?」
- 「新しく追加されたテキストだけ翻訳したい」
使い方
- 新バージョンの英語XMLを左に貼り付けます。
- 旧バージョンの英語XMLまたは日本語XMLを右に貼り付けます。
- 「比較する」を押すと、UUID単位で差分が解析されます。
- 結果は「原文」「状態」「備考」の3カラムで表示されます。
JAなし(未訳)や本文差異(変更あり)があれば、その箇所を重点的に確認してください。
つまり、どういうことだってばよ?
たとえば、火ダメージを与える呪文があるとします。
MODのアップデートで、その効果が次のように変わったとします。
- 新バージョン:火ダメージを 2d6 与える
- 旧バージョン:火ダメージを 1d8 与える
このとき、英語版と日本語版をそのまま比較すると、こうなります。
問題はここです。
機械的に「本文差異」とだけ見て「翻訳済みだからOK」と判断してしまうと、実際にはテキストの中身が変わっているのに気づかないままになります。
つまり、「効果が1d8→2d6に変わった」という重要な仕様変更を見落とすわけです。
これを防ぐために、まず最初に「新旧の英語版どうし」で比較します。
英語版は常に正本なので、この比較でテキスト更新があれば確実に検出できます。
- すべて「一致」なら、英語版では変更なし(つまり翻訳もそのままでOK)
- 「本文差異」があれば、テキストが変更されている
- 「JAなし」は、新しく追加されたテキストで翻訳が必要な箇所
この段階で、MODの更新範囲を正確に把握できます。
その上で、日本語版と突き合わせれば、どこを追訳・修正すべきかがはっきりします。
なお、開発者が英語版の version をちゃんと上げてくれている場合は、最初から英語版と日本語版を直接比較しても「本文差異+version差異」として検出されるので、変更箇所を見逃すことはありません。
けれど現実には version を上げ忘れているMOD作者も多いので、確実を期すならまず英語版の新旧比較を行うのが鉄則です。
便利な機能
- JAをEN順に整形
右側(日本語版XML)を左側(英語版XML)のUUID順に並べ替えます。
英語版の並びに合わせることで、どの項目が対応しているかをすぐ確認できます。
レビューや翻訳チェック時に最初に使うと便利。 - JA整形(順序維持)
順序はそのままに、余分な空白や改行を整えます。
XMLの見た目をきれいに保ちたいときに。 - JA欠落をENで補完
日本語版に存在しないUUIDを、英語版からコピーして「空欄のテンプレート」を作ります。
新規追加テキストを漏れなく翻訳したいときに使うと最強。
あとでAI翻訳や手動訳を入れる土台になります。 - verをENに合わせる
右側(日本語XML)のversion属性を、左側(英語XML)と同じ値に揃えます。
本文はそのまま。英語側の更新に合わせてバージョンだけ同期したいときに使います。 - JAなしをコピー
未訳のUUID(JAなし)だけを抽出してクリップボードにコピーします。
AI翻訳や外注翻訳に回すときの素材作りに便利。
「新規追加分だけ翻訳したい」という用途にぴったり。 - クリア
入力・結果を一括でリセットします。新しい比較を始める前に。
翻訳照合(MODと公式の突き合わせ)
MOD英語XMLに含まれるテキストを、公式の英語/日本語ファイルと照らし合わせ、既存の公式訳を自動で拾い上げます。MODのテキストの中に「公式ゲームと全く同じ文言」が含まれていないかを事前チェックし、無駄な翻訳作業と公式訳との不整合を防ぐ機能です。
この機能は、MODの英語XMLと公式データ(英語/日本語)を照らし合わせて、
「公式訳がそのまま使える部分」と「新しく翻訳が必要な部分」を自動で振り分けます。MODのテキストの中に「公式ゲームと全く同じ文言」が含まれていないかを事前チェックし、無駄な翻訳作業と公式訳との不整合を防ぐ機能です。
なぜ重要?
- MODに公式と全く同じテキストがある場合、すでにゲーム内に公式訳が存在するが、UUIDが違うのでチェックが困難
- それを知らずに独自翻訳すると→公式訳と表現が食い違う→プレイヤーが混乱
- 事前に見つけておけば→翻訳作業をスキップ→公式訳をそのまま流用
使い方
- タブから「翻訳照合」を開き、MODの英語XMLを選択。
- 公式データのフォルダ(EN/JA)を指定。空欄のままでもOK。既定で
data\bundles\bg3_officialを使用します。 - 必要なら「あいまい一致(fuzzy)」をONにして、類似文も拾う設定にします。
cutoff(一致度のしきい値)は 0.92推奨。PCが速ければ workers を2〜4に上げると処理が速くなります。 - 「照合して生成」を押すと、照合作業が始まります。
完了後は結果を保存するか、「比較へ移行」で差分タブに直接送って確認できます。
出力結果
matched.xml: 照合に成功した行(既に公式訳が存在するもの、再翻訳不要)unmatched.xml: 公式にないテキスト(MOD独自部分→翻訳が必要)review.csv: fuzzy一致を有効にした場合の検証用ファイル。似ているが完全一致ではないもの(要確認)
とくにfuzzy一致機能を使う場合、便利なのですが気を付けないといけない点が多いので下記をよく読んでください。
fuzzy一致について(詳細解説)
fuzzy一致とは?
「完全に同じではないが、似ているテキスト」も候補として検出する機能です。公式テキストとMODテキストが微妙に違うけれど実質的には同じ内容の場合を拾い上げます。
なぜfuzzy一致が必要?
ケース1:句読点や記号の違い
公式:"Cast a spell that deals 2d6 fire damage."
MOD: "Cast a spell that deals 2d6 fire damage"→末尾のピリオドの有無だけで「別物」扱いされてしまう
ケース2:スペースや改行の違い
公式:"Restores 50 hit points immediately."
MOD: "Restores 50 hit points immediately."→スペースが多いだけで「一致しない」判定
ケース3:大文字小文字の違い
公式:"magic Missile"
MOD: "Magic Missile"→実質同じなのに「不一致」になる
ケース4:軽微な表現変更
公式:"Deals 1d8 piercing damage to target."
MOD: "Deals 1d8 piercing damage to the target."→”target”と”the target”で本質的には同じ
cutoff値の意味
cutoff = 0.8(既定値)
- 80%以上似ていれば候補として表示
- 推奨設定:ほとんどのケースでこれで十分
cutoff = 0.9(厳密)
- 90%以上の類似度が必要
- 誤候補は減るが、有用な候補も見逃しやすい
cutoff = 0.7(緩い)
- 70%以上で候補表示
- より多くの候補が出るが、関係ない文章も混入しやすい
fuzzy一致は「公式訳の見逃し防止」と「翻訳作業の最適化」のための保険機能です。完璧を求めず、cutoff 0.8で一度走らせ、review.csvで気になる候補だけチェックするのが実用的な使い方です。
運用のコツ
まずこの照合で「公式訳を流用できる部分」を確定させます。
その後、unmatched.xml だけをAI翻訳に回すと、作業時間が大幅に短縮できます。
fuzzyをONにした場合は、誤マッチが入りやすいので review.csv を必ずチェックしてください。cutoffを下げすぎると「似てるけど違う文」が混ざるため、まずはデフォルトの0.92で試すのが安全です。
この機能を使えば、「どこを訳すべきか」「どこはすでに訳されているか」が一目でわかります。
つまり、“翻訳前の仕分け”を自動でやってくれる下準備ツールです。
大規模なMOD翻訳では、これをやるだけで全体の手間が半分以下になります。
(特にオリジンキャラの会話を補完したり修正する系のMODには大変有用です)
比較へ移行ボタンについて
MOD照合の結果を、そのまま比較タブで確認することができるボタンです。ファイルを手動でコピペする手間が省けます。
使い方
Step 1:MOD照合を実行
- MODの英語XMLと公式データを照合
matched.xml、unmatched.xml、review.csvが生成される
Step 2:「比較へ移行」をクリック
matched.xmlが自動で比較画面に読み込まれる- 左欄:元のMOD英語テキスト
- 右欄:公式訳が適用されたバージョン
Step 3:即座に差分確認
- 「JAなし」:まだ翻訳が必要な部分
- 「一致」:公式訳が適用済みの部分
- 一目で「どこが埋まって、どこが残っているか」が分かる
ツールチップ挿入機能
ゲーム内用語に <LSTag Tooltip="..."> を自動で挿入し、公式のツールチップ仕様に合わせた形へ整えます。
「セーヴィング・スロー」や「知力」など、辞書に登録した用語をXML本文内で検出し、自動的にタグ化してくれるツールです。
この機能は、XML本文(とくに <content> の中身)に用語辞書を適用して、該当語を自動的に <LSTag> で包みます。
辞書は「用語 → Tooltip名/Type」の対応表になっており、
たとえばセーヴィング・スロー → SavingThrow のように登録しておくと、本文中の一致箇所にタグを差し込みます。
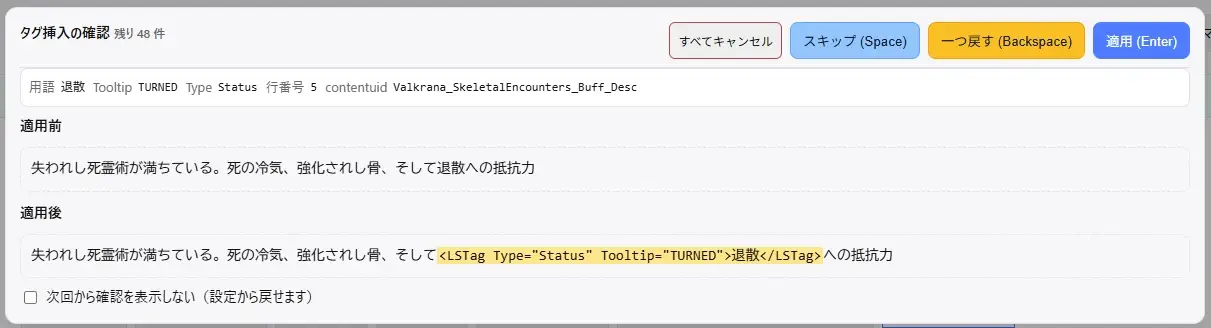
- 既にタグが入っている箇所は壊さずに避け、タグ境界も検出して安全にスキップします。
- 長い語を優先的に当て、挿入タグは常にエスケープ表記(
<と>)で出力されるため、XML構造を壊しません。 - 使い方の流れはシンプルで、「XMLを貼る → 辞書を整える → 適用 → 確認 → コピー」です。
なぜ重要?
AI翻訳を使って生成されたMODテキストでは、ツールチップがまったく設定されていないケースが非常に多くあります。
あるいは「この行にはあるけど、こっちは無い」というように、タグの付け方にムラがあるパターンもよく見られます。
手作業で補うのは現実的ではなく、抜けや重複が発生しやすい。
その結果、ゲーム内で本来表示されるべき用語説明が出なかったり、Tooltipのリンクが切れたりします。
この機能は、その抜けを自動で補完し、機械的にすべての対応箇所に正しいタグを挿入します。
つまり、ツールチップの網羅性を100%に近づけ、人間のミスを完全に排除できる仕組みです。
使い方
まず最初に辞書を作ります。
- ツールチップ挿入ページ下部の「ファイルを選択」を開き、公式の日本語XMLを読み込みます。
- 公式の日本語XMLは、
Baldurs Gate 3\Data\Localization\Japanese\Japanese.pakを解凍してできた、japanese.loca.xmlを指定してください。 .pakファイルの解凍はBG3 Modder’s Multitoolを使用し、ツールのDrop mod workspace folder or a mod .pak hereにjapanese.pakをドラッグ&ドロップすると、BG3 Modder’s Multitoolのフォルダ内にあるUnpackedModsフォルダに解凍したファイルが生成されます。
- 公式の日本語XMLは、
- 件数を指定(推奨は
150)して、頻出抽出を押します。 - 公式訳で頻出している順で、ツールチップが表示されます。
- 辞書に登録したいツールチップを選択するか、すべて選択し
選択を辞書へ追加ボタンを押します。 - これで、公式で使われているタグ仕様をそのまま辞書化できます。
辞書を整えたら、XMLを貼って挿入します。
- 左ペインに翻訳済みのXMLを貼る。
- 右上の
辞書を管理から、用語とTooltip名を登録。
例:「セーヴィング・スロー → SavingThrow」「修正値 → AbilityModifier」 適用ボタンを押すと、自動的にタグが挿入されます。- 確認モードでは1件ずつプレビューしながら進められ、慣れたら自動モードに切り替え可能。
- 挿入結果は右ペインに即反映され、コピーやダウンロードで出力できます。
出力の特徴
- タグは常にエスケープ表記(
<LSTag>...</LSTag>)で出力されるため、XML構造を壊しません。 - 既に存在するタグは完全に保護され、二重適用されることはありません。
- 「ボーナス・アクション」と「アクション」のように重なる語は、長い方を優先して処理します。
- 戻る機能も搭載。直前の適用をその場で取り消せます。
すべてキャンセルボタンを押すと、それまでの作業をすべて放棄して完全に最初に戻ります。
辞書の仕組み
- 用語辞書はブラウザ内に保存され、再起動後も保持されます。
- 登録した内容はJSON形式でローカルに記録され、次回起動時にも自動で読み込まれます。
- 辞書の編集・削除・CSVインポートも可能です。
- CSV形式はシンプルで、1行に「用語, Tooltip名」を書くだけです。
確認ダイアログ表示中のキー操作
これは作業しやすいかなと思い実装した機能です。
- Enter: 適用
- Space: スキップ
- Backspace: 一つ戻す(直前の適用を取り消し、前の候補に戻る)
おわりに
翻訳は最終的に「遊ぶ人の体験」を左右する部分。
キャラ名やスキル名が毎回バラバラだと immersion(没入感)が崩れてしまいます。
逆に、統一された自然な日本語が流れると、それだけでゲームの楽しさが倍増します。
このツールを使いこなして、
AIのスピード×辞書の精度×人のチェック という三位一体の翻訳環境を作り、
ぜひ快適な日本語化MODライフを楽しんでください。
寄付も受け付けてます
何卒宜しくお願い致します🥺






コメント
コメント一覧 (6件)
セール中にバルダーズクエスト3買ったので助かります!洋ゲーのmodって凄い作品ばっかりなのに日本語でプレイできないのだけがネックなんですよね。翻訳してくれている人には感謝しかないんですが、自分でも簡単な翻訳が出来るツールがあればと思っていたので……。本当にベストタイミングでした!
ありがとうございます!
ちょうど良いタイミングで使っていただけて嬉しいです。
また機能追加したりしてるんで、たまに見に来て下さい。
はじめまして、こちらのツールを最近見させていただきました。
記事の内容も分かりやすく、便利で製作者様には感謝しかありません。
いくつかのmodは翻訳できたのですが
https://www.nexusmods.com/baldursgate3/mods/10431?tab=description
このmodの翻訳ファイルが反映されず困っています。
english.xmlを日本語にするとゲーム内の説明文が「not fonud」になり
Japaneseフォルダを作成してJapanese.xmlを作成してpekファイルを生成しても反映されず。
meta.lsxをいじるといいとredditの記事も見たのですが
全くわからず…ここで質問するのは失礼かなとも思ったのですがコメントさせていただきました。
何か助言などいただければ幸いです。
こちらでも日本語化してみましたが、問題なく表示されますね。
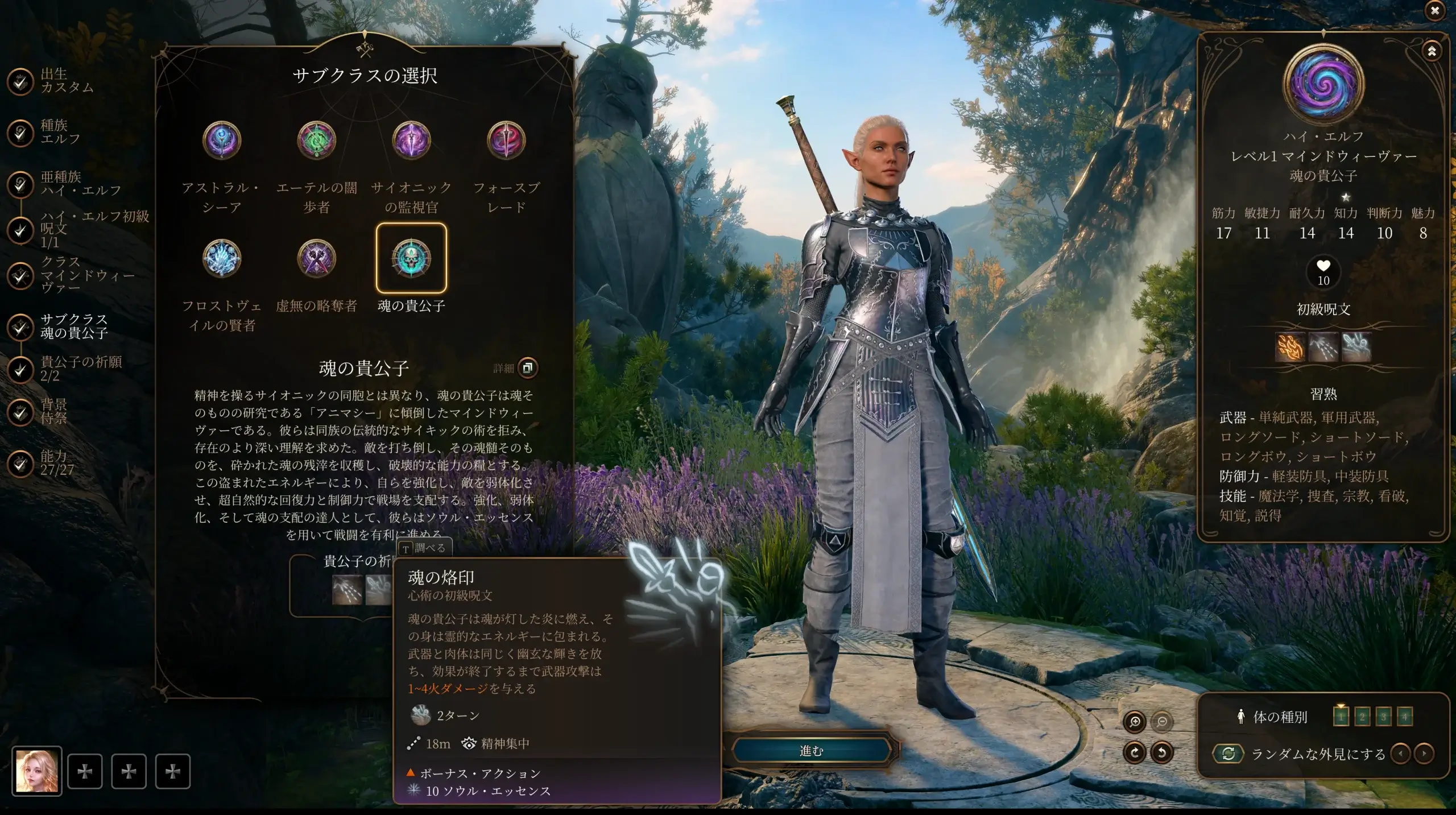
日本語化MODは独自に作成していますか?
その場合、下記のようなフォルダ構造で格納されているでしょうか?
日本語化MOD名/
└─ Mods/
└─ MindWeaver_63d2a82d-84e1-05be-60a3-fffddbacfba8/
└─ Localization/
└─ Japanese/
└─ japanese.xml
参考に当サイトで配布している日本語化MODのmeta.lsxを記載しておきます。
こんにちわ返信ありがとうございます。
投稿後に再度確認してみましたが、私の作ったmodに入れていた
metaファイルの記述が一部(フォルダの位置)が間違っていたようです。
modの日本語化もしてくださりとてもうれしいです!
お手数をおかけしました!
このツールのおかげでAngel Themed Race and Classの日本語化できました
ツール公開ありがとうございます