TTW3.4への日本語音声を作成するにあたり、TaleOfTwoWastelands.esmで追加・変更されたすべての音声ファイルとテキストを抜き出す必要がありました。
そして、それだけやって、力尽きました。2000ほどの音声ファイルを切り貼りしてTTWで編集された英語版に合わせるのはマジで面倒くさすぎる。lipファイルも再生成する手順忘れてしまったし、G.E.C.K入れるところからやり直さねばならない…
つくったFNVEditのスクリプト
Export_TTW_Dialog_Changes.pasとかで保存して、FNVEdit\Edit Scriptsの中に入れれば使えます。
長いので展開してね。
Export_TTW_Dialog_Changes.pas
unit userscript;
var
output: TStringList;
dataPath: string;
voiceExts: TStringList;
function BoolToStrEx(b: boolean): string;
begin
if b then Result := 'True' else Result := 'False';
end;
function Initialize: integer;
var
i: Integer;
f: IInterface;
fname: string;
begin
output := TStringList.Create;
output.Add('Plugin,FormID,ResponseIndex,BaseSpeaker,NewSpeaker,BaseText,NewText,BaseVoiceFile,NewVoiceFile');
dataPath := ProgramPath + '..\Data\';
voiceExts := TStringList.Create; // kept for future use
voiceExts.Add('.ogg');
voiceExts.Add('.wav');
voiceExts.Add('.mp3');
for i := 0 to FileCount - 1 do begin
f := FileByIndex(i);
fname := GetFileName(f);
end;
Result := 0;
end;
function CsvEscape(const s: string): string;
var
tmp: string;
begin
tmp := StringReplace(s, '"', '""', [rfReplaceAll]);
Result := '"' + tmp + '"';
end;
function GetPreviousOverrideBeforeFile(info: IInterface; const targetFileName: string): IInterface;
var
base: IInterface;
prev: IInterface;
cur: IInterface;
i: Integer;
curFile: string;
begin
Result := nil;
base := MasterOrSelf(info);
prev := base;
if SameText(GetFileName(GetFile(base)), targetFileName) then Exit;
for i := 0 to OverrideCount(base) - 1 do begin
cur := OverrideByIndex(base, i);
curFile := GetFileName(GetFile(cur));
if SameText(curFile, targetFileName) then begin
Result := prev;
Exit;
end;
prev := cur;
end;
end;
function GetSpeakerNameFromInfo(e: IInterface): string;
var
spk, ln, conds, cond, refObj: IInterface;
i: Integer;
fn: string;
begin
Result := '';
spk := ElementByPath(e, 'ANAM - Speaker');
if Assigned(spk) then begin
ln := LinksTo(spk);
if Assigned(ln) then begin
Result := GetElementEditValues(ln, 'FULL - Name');
if Result = '' then Result := GetElementEditValues(ln, 'EDID');
Exit;
end;
end;
conds := ElementByPath(e, 'Conditions');
if not Assigned(conds) then Exit;
for i := 0 to ElementCount(conds) - 1 do begin
cond := ElementByIndex(conds, i);
fn := GetElementEditValues(cond, 'Function');
if fn = 'GetIsID' then begin
refObj := LinksTo(ElementByPath(cond, 'Referenceable Object'));
if Assigned(refObj) then begin
Result := GetElementEditValues(refObj, 'FULL - Name');
if Result = '' then Result := GetElementEditValues(refObj, 'EDID');
Exit;
end;
end;
end;
end;
function GetResponseCount(info: IInterface): Integer;
var
responses: IInterface;
begin
Result := 0;
responses := ElementByPath(info, 'Responses');
if Assigned(responses) then begin
Result := ElementCount(responses);
Exit;
end;
if Assigned(ElementByPath(info, 'NAM1 - Response Text')) then begin
Result := 1;
Exit;
end;
end;
function GetResponseTextByIndex(info: IInterface; index: integer): string;
var
responses: IInterface;
res: IInterface;
begin
Result := '';
responses := ElementByPath(info, 'Responses');
if not Assigned(responses) then Exit;
if (index < 0) or (index >= ElementCount(responses)) then Exit;
res := ElementByIndex(responses, index);
Result := GetElementEditValues(res, 'NAM1 - Response Text');
if Result = '' then
Result := GetElementEditValues(res, 'Response Text');
if Result = '' then
Result := GetElementEditValues(res, 'NAM1');
end;
function ResolveVoiceTypeEdid(info: IInterface): string;
var
spk, ln, vt, conds, cond, vref: IInterface;
i: Integer;
fn: string;
begin
Result := '';
spk := ElementByPath(info, 'ANAM - Speaker');
if Assigned(spk) then begin
ln := LinksTo(spk);
if Assigned(ln) then begin
vt := ElementByPath(ln, 'VTCK - Voice Type');
if Assigned(vt) then begin
vt := LinksTo(vt);
if Assigned(vt) then begin
Result := GetElementEditValues(vt, 'EDID');
if Result <> '' then Exit;
Result := GetElementEditValues(vt, 'FULL - Name');
if Result <> '' then Exit;
end;
end;
end;
end;
conds := ElementByPath(info, 'Conditions');
if Assigned(conds) then begin
for i := 0 to ElementCount(conds) - 1 do begin
cond := ElementByIndex(conds, i);
fn := GetElementEditValues(cond, 'Function');
if fn = 'GetIsVoiceType' then begin
vref := LinksTo(ElementByPath(cond, 'Voice Type'));
if Assigned(vref) then begin
Result := GetElementEditValues(vref, 'EDID');
if Result = '' then Result := GetElementEditValues(vref, 'FULL - Name');
if Result <> '' then Exit;
end;
end;
end;
end;
end;
function GetResponseNumberByIndex(info: IInterface; index: integer): integer;
var
responses: IInterface;
res: IInterface;
begin
Result := index + 1;
responses := ElementByPath(info, 'Responses');
if not Assigned(responses) then Exit;
if (index < 0) or (index >= ElementCount(responses)) then Exit;
res := ElementByIndex(responses, index);
try
Result := GetElementNativeValues(res, 'TRDT\Response number');
except
end;
end;
function BuildVoiceRelPathLower(pluginName, voiceTypeEdid, fileName: string): string;
var
p, v, f: string;
begin
if voiceTypeEdid = '' then voiceTypeEdid := '(unknown)';
p := LowerCase(pluginName);
v := LowerCase(voiceTypeEdid);
f := LowerCase(fileName);
Result := 'sound\voice\' + p + '\' + v + '\' + f;
end;
function ResolveQuestOfInfo(info: IInterface): IInterface;
var
q, dial: IInterface;
begin
Result := nil;
// INFO -> QSTI direct
q := ElementByPath(info, 'QSTI');
if Assigned(q) then begin
q := LinksTo(q);
if Assigned(q) and (Signature(q) = 'QUST') then begin
Result := q;
Exit;
end;
end;
// Fallback: via DIAL link at index 0 -> QNAM - Quest
dial := LinksTo(ElementByIndex(info, 0));
if Assigned(dial) and (Signature(dial) = 'DIAL') then begin
q := ElementByPath(dial, 'QNAM - Quest');
if Assigned(q) then begin
q := LinksTo(q);
if Assigned(q) and (Signature(q) = 'QUST') then
Result := q;
end;
end;
end;
function GetTopicOfInfo(info: IInterface): IInterface;
var
dial: IInterface;
begin
Result := nil;
dial := LinksTo(ElementByIndex(info, 0));
if Assigned(dial) and (Signature(dial) = 'DIAL') then
Result := dial;
end;
function LOHexMasked8(info: IInterface): string;
begin
Result := LowerCase(IntToHex(GetLoadOrderFormID(info) and $00FFFFFF, 8));
end;
function AutoVoiceFilenameGECK(info, quest, dial: IInterface; respNum: integer): string;
var
qid, did: string;
qlen, dlen: integer;
hex: string;
begin
qid := '';
did := '';
if Assigned(quest) then qid := GetElementEditValues(quest, 'EDID');
if Assigned(dial) then did := GetElementEditValues(dial, 'EDID');
qlen := Length(qid);
dlen := Length(did);
if qlen + dlen > 25 then begin
if qlen > 10 then begin
qlen := 10;
dlen := 15;
end else
dlen := 10 - qlen + 15;
end;
hex := LOHexMasked8(info);
Result := LowerCase(Copy(qid, 1, qlen) + '_' + Copy(did, 1, dlen) + '_' + hex + '_' + IntToStr(respNum) + '.ogg');
end;
function Process(e: IInterface): integer;
var
cur: IInterface;
win: IInterface;
prev: IInterface;
curFileName: string;
winFileName: string;
prevFileName: string;
baseCount, curCount, maxCount: Integer;
idx: Integer;
baseText, newText: string;
baseVoiceType, newVoiceType: string;
baseRel, newRel: string;
formIdHex: string;
formIdOut: string;
anyChange: boolean;
row: string;
respNumBase, respNumNew: Integer;
baseSpeaker, newSpeaker: string;
pluginPrevForVoice, pluginNewForVoice: string;
questPrev, questNew: IInterface;
dialPrev, dialNew: IInterface;
fileBase, fileNew: string;
begin
Result := 0;
if Signature(e) <> 'INFO' then Exit;
cur := e;
curFileName := GetFileName(GetFile(cur));
win := WinningOverride(cur);
winFileName := GetFileName(GetFile(win));
prev := GetPreviousOverrideBeforeFile(cur, curFileName);
if Assigned(prev) then
prevFileName := GetFileName(GetFile(prev))
else
prevFileName := '';
pluginNewForVoice := winFileName;
if prevFileName <> '' then
pluginPrevForVoice := prevFileName
else
pluginPrevForVoice := curFileName;
// resolve quest/topic for filename generation
questNew := ResolveQuestOfInfo(cur);
dialNew := GetTopicOfInfo(cur);
questPrev := ResolveQuestOfInfo(prev);
dialPrev := GetTopicOfInfo(prev);
baseCount := 0; curCount := 0; maxCount := 0;
if Assigned(prev) then baseCount := GetResponseCount(prev);
curCount := GetResponseCount(cur);
if baseCount > curCount then maxCount := baseCount else maxCount := curCount;
formIdHex := IntToHex(FixedFormID(cur), 8);
formIdOut := '''' + formIdHex;
if Assigned(prev) then baseVoiceType := ResolveVoiceTypeEdid(prev) else baseVoiceType := '';
newVoiceType := ResolveVoiceTypeEdid(win);
if Assigned(prev) then baseSpeaker := GetSpeakerNameFromInfo(prev) else baseSpeaker := '';
newSpeaker := GetSpeakerNameFromInfo(cur);
for idx := 0 to maxCount - 1 do begin
if Assigned(prev) then baseText := GetResponseTextByIndex(prev, idx) else baseText := '';
newText := GetResponseTextByIndex(cur, idx);
if Assigned(prev) then respNumBase := GetResponseNumberByIndex(prev, idx) else respNumBase := GetResponseNumberByIndex(cur, idx);
respNumNew := GetResponseNumberByIndex(cur, idx);
if Assigned(prev) then
fileBase := AutoVoiceFilenameGECK(prev, questPrev, dialPrev, respNumBase)
else
fileBase := '';
fileNew := AutoVoiceFilenameGECK(cur, questNew, dialNew, respNumNew);
if Assigned(prev) then
baseRel := BuildVoiceRelPathLower(pluginPrevForVoice, baseVoiceType, fileBase)
else
baseRel := '';
newRel := BuildVoiceRelPathLower(pluginNewForVoice, newVoiceType, fileNew);
anyChange := False;
if Assigned(prev) then begin
anyChange := Trim(baseText) <> Trim(newText);
end else begin
anyChange := True;
end;
if not anyChange then Continue;
row := CsvEscape(curFileName) + ',' + CsvEscape(formIdOut) + ',' + IntToStr(idx + 1) + ',' +
CsvEscape(baseSpeaker) + ',' + CsvEscape(newSpeaker) + ',' +
CsvEscape(baseText) + ',' + CsvEscape(newText) + ',' +
CsvEscape(ExtractFileName(baseRel)) + ',' + CsvEscape(ExtractFileName(newRel));
output.Add(row);
end;
end;
function Finalize: integer;
var
outPath: string;
timestamp: string;
begin
timestamp := FormatDateTime('yyyymmdd_hhnnss', Now);
outPath := ProgramPath + 'TTW_Dialog_Changes_' + timestamp + '.csv';
output.SaveToFile(outPath);
output.Free;
voiceExts.Free;
AddMessage('Exported to: ' + outPath + ' (rows: ' + IntToStr(output.Count) + ')');
Result := 0;
end;
end.
こいつをTTWのesmとかに当てると、原語に手を加えているダイアログを抽出して、そのセリフに対応する音声ファイル名が全部まとめて出力されます。
- esmにスクリプトを適用
- まずダイアログに変更が加えられている(レコードを弄っている)部分を調べる
- 検知したレコードの話者、FormID、ダイアログ、セリフの音声ファイル名をリスト化
- これは変更前・変更後どちらも抽出する
- データをcsvに出力
あとは人間がcsvを見て、フムフム、とやったり、さらにスクリプトをかけて自由に処理する感じ。
CSVに日本語化データを入れ込む
これはFNVEditのスクリプトでも可能だったかもしれないが、面倒なのでPythonで実装した。
AddTTWJPColumns.py
"""
AddTTWJPColumns
----------------
TTW Dialog Changes の CSV に、日本語テキストとその出典情報(辞書ファイル/行番号)を自動で追加するツール。
FOJP の fojp.xml に記載された辞書を読み込み、BaseText/NewText の英語に対応する日本語を追記します。
・GUI/CLI 両対応(GUI 推奨)
・追加列: BaseTextJP, BaseTextJP_Source, BaseTextJP_Line, NewTextJP, NewTextJP_Source, NewTextJP_Line
・辞書優先度: fojp.xml の priority(小さいほど高優先度)に従って採用
・type=2(ID付き)辞書はキー一致、type=1 は行位置一致、directory はファイル全文対応(行番号0)
必要: Python 3.8+(GUI は tkinter が必要)
"""
import argparse
import csv
import os
import sys
import shutil
from typing import Dict, Tuple, List, Optional
import xml.etree.ElementTree as ET
import threading
import importlib
import subprocess
# 公開向け・汎用ヘルプテキスト(GUI の「説明」タブで表示)
HELP_TEXT = (
"概要\n"
"TTW Dialog Changes の CSV に、日本語テキストと出典(辞書ファイル/行番号)を追加します。\n"
"FOJP の fojp.xml を読み込み、BaseText/NewText の英語に対応する日本語を検索して追記します。\n"
"\n"
"追加列\n"
"- BaseTextJP / BaseTextJP_Source / BaseTextJP_Line\n"
"- NewTextJP / NewTextJP_Source / NewTextJP_Line\n"
"該当なしは空欄。CSVはUTF-8で出力します。\n"
"\n"
"使い方(GUI)\n"
"1) スクリプトを起動(例: python ./AddTTWJPColumns.py --gui)\n"
"2) 変換タブで fojp.xml と CSV、(任意で)出力フォルダを指定\n"
"3) 必要なら「辞書ディレクトリも含める」をオン\n"
"4) 実行ボタンを押すと処理開始\n"
"\n"
"使い方(CLI)\n"
"python ./AddTTWJPColumns.py --fojp ./fojp.xml --csv ./file.csv\n"
"複数CSV: --csv a.csv b.csv / ディレクトリ辞書: --include-dirs\n"
"\n"
"マッピング仕様\n"
"- priority(小さいほど高優先)順に辞書を適用\n"
"- type=2(ID付き): キー一致で対応(行番号は日本語側の行)\n"
"- type=1(通常): 英文と和文の同位置行を対応\n"
"- directory: 同名ファイル同士を全文対応(行番号0)\n"
"- 同一英語が複数候補の場合は priority が小さいものを採用\n"
"\n"
"注意/トラブルシュート\n"
"- CSVを開いた状態だと上書きできないことがあります(出力フォルダ指定推奨)\n"
"- GUI が起動しない場合は tkinter の有無を確認してください\n"
)
try:
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
except Exception:
tk = None
ttk = None
filedialog = None
messagebox = None
def _run_pip_install(package: str) -> bool:
try:
print(f"[情報] 足りないモジュールをインストール試行: {package}")
cmd = [sys.executable, '-m', 'pip', 'install', '--disable-pip-version-check', '--user', package]
proc = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, text=True)
print(proc.stdout)
return proc.returncode == 0
except Exception as e:
print(f"[警告] pipインストールに失敗しました: {package}: {e}")
return False
def ensure_tkinter_available() -> bool:
"""Ensure tkinter (GUI deps) is available. Try pip-install common names as a last resort."""
global tk, ttk, filedialog, messagebox
if tk is not None:
return True
# Try pip-installing likely package names (may not work on all platforms)
for pkg in ('tkinter', 'tk'):
if _run_pip_install(pkg):
try:
tk = importlib.import_module('tkinter')
ttk = importlib.import_module('tkinter.ttk')
filedialog = importlib.import_module('tkinter.filedialog')
messagebox = importlib.import_module('tkinter.messagebox')
return True
except Exception:
pass
# Final attempt to import without pip success (in case OS packages were installed concurrently)
try:
tk = importlib.import_module('tkinter')
ttk = importlib.import_module('tkinter.ttk')
filedialog = importlib.import_module('tkinter.filedialog')
messagebox = importlib.import_module('tkinter.messagebox')
return True
except Exception:
pass
print('[警告] tkinterが見つかりません。この環境ではGUIは使用できません。')
print(' Linuxの場合はOSパッケージ(例: sudo apt install python3-tk)をインストールしてください。')
return False
def read_all_lines(path: str, encoding: str) -> List[str]:
with open(path, 'r', encoding=encoding, errors='replace', newline='') as f:
return [line.rstrip('\n').rstrip('\r') for line in f]
def split_keyed_line(line: str) -> Optional[Tuple[str, str]]:
if not line:
return None
idx = line.find('\t')
if idx < 0:
return None
return line[:idx], line[idx + 1:]
class DictionaryMap:
def __init__(self) -> None:
# english_text -> (japanese_text, source_rel_path, line_number, priority)
self.map: Dict[str, Tuple[str, str, int, int]] = {}
def add(self, english: str, japanese: str, source: str, line: int, priority: int) -> None:
if english is None or japanese is None:
return
en_key = english.strip()
jp_val = japanese.strip()
if not en_key:
return
if en_key not in self.map:
self.map[en_key] = (jp_val, source or '', int(line), int(priority))
return
# keep the mapping with the better (lower) priority
_, _, _, existing_pri = self.map[en_key]
if priority < existing_pri:
self.map[en_key] = (jp_val, source or '', int(line), int(priority))
def norm_path_for_csv(p: str) -> str:
return p.replace('\\', '/')
def build_en_to_jp_map(fojp_xml_path: str, include_dirs: bool = False) -> DictionaryMap:
root_dir = os.path.dirname(os.path.abspath(fojp_xml_path))
tree = ET.parse(fojp_xml_path)
root = tree.getroot()
repl = root.find('replacetext')
if repl is None:
raise RuntimeError('replacetext not found in fojp.xml')
nodes = [n for n in list(repl) if isinstance(n.tag, str)]
def get_priority(n: ET.Element) -> int:
p = n.get('priority')
try:
return int(p) if p is not None and str(p).strip() != '' else 10
except Exception:
return 10
nodes.sort(key=get_priority)
mapping = DictionaryMap()
for n in nodes:
name = n.tag
pri = get_priority(n)
if name == 'file':
jp_rel = n.get('jp') or ''
en_rel = n.get('en') or ''
type_attr = n.get('type')
dtype = int(type_attr) if (type_attr and type_attr.strip().isdigit()) else 1
jp_path = os.path.join(root_dir, jp_rel)
en_path = os.path.join(root_dir, en_rel)
if not (os.path.isfile(jp_path) and os.path.isfile(en_path)):
continue
if dtype == 2:
en_lines = read_all_lines(en_path, 'utf-8')
jp_lines = read_all_lines(jp_path, 'cp932')
en_by_id: Dict[str, Tuple[str, int]] = {}
jp_by_id: Dict[str, Tuple[str, int]] = {}
for idx, line in enumerate(en_lines):
kv = split_keyed_line(line)
if kv:
en_by_id[kv[0]] = (kv[1], idx + 1)
for idx, line in enumerate(jp_lines):
kv = split_keyed_line(line)
if kv:
jp_by_id[kv[0]] = (kv[1], idx + 1)
for _id, (en_text, _) in en_by_id.items():
if _id in jp_by_id:
jp_text, jp_line = jp_by_id[_id]
mapping.add(en_text, jp_text, norm_path_for_csv(jp_rel), jp_line, pri)
else:
en_lines = read_all_lines(en_path, 'utf-8')
jp_lines = read_all_lines(jp_path, 'cp932')
count = min(len(en_lines), len(jp_lines))
for i in range(count):
mapping.add(en_lines[i], jp_lines[i], norm_path_for_csv(jp_rel), i + 1, pri)
elif name == 'directory' and include_dirs:
jp_rel = n.get('jp') or ''
en_rel = n.get('en') or ''
jp_dir = os.path.join(root_dir, jp_rel)
en_dir = os.path.join(root_dir, en_rel)
if not (os.path.isdir(jp_dir) and os.path.isdir(en_dir)):
continue
for dirpath, _, filenames in os.walk(en_dir):
for fname in filenames:
en_full = os.path.join(dirpath, fname)
rel = os.path.relpath(en_full, en_dir)
jp_full = os.path.join(jp_dir, rel)
if not os.path.isfile(jp_full):
continue
try:
en_content = open(en_full, 'r', encoding='utf-8', errors='replace').read().strip()
jp_content = open(jp_full, 'r', encoding='cp932', errors='replace').read().strip()
if en_content and jp_content:
src_rel = norm_path_for_csv(os.path.join(jp_rel, rel))
mapping.add(en_content, jp_content, src_rel, 0, pri)
except Exception:
pass
return mapping
def ensure_field_order(orig_fields: List[str]) -> List[str]:
# Desired inserts
after_base = ['BaseTextJP', 'BaseTextJP_Source', 'BaseTextJP_Line']
after_new = ['NewTextJP', 'NewTextJP_Source', 'NewTextJP_Line']
fields = list(orig_fields)
# Insert after BaseText
if 'BaseText' in fields:
idx = fields.index('BaseText') + 1
for col in after_base:
if col not in fields:
fields.insert(idx, col)
idx += 1
else:
for col in after_base:
if col not in fields:
fields.append(col)
# Insert after NewText
if 'NewText' in fields:
idx = fields.index('NewText') + 1
for col in after_new:
if col not in fields:
fields.insert(idx, col)
idx += 1
else:
for col in after_new:
if col not in fields:
fields.append(col)
return fields
def augment_csv(
csv_path: str,
mapping: DictionaryMap,
output_path: Optional[str] = None,
output_encoding: str = 'utf-8-sig',
delimiter: str = ',',
quote_all: bool = True,
) -> None:
if not os.path.isfile(csv_path):
print(f"[WARN] CSV not found: {csv_path}")
return
print(f"Processing CSV: {csv_path}")
with open(csv_path, 'r', encoding='utf-8', errors='replace', newline='') as f:
reader = csv.DictReader(f)
rows = list(reader)
fieldnames = reader.fieldnames or []
fieldnames = ensure_field_order(fieldnames)
out_rows: List[Dict[str, str]] = []
for row in rows:
base_text = (row.get('BaseText') or '').strip()
new_text = (row.get('NewText') or '').strip()
base_jp = ''
base_src = ''
base_line = ''
new_jp = ''
new_src = ''
new_line = ''
if base_text in mapping.map:
jp, src, ln, _ = mapping.map[base_text]
base_jp = jp
base_src = src
base_line = str(ln)
if new_text in mapping.map:
jp, src, ln, _ = mapping.map[new_text]
new_jp = jp
new_src = src
new_line = str(ln)
row['BaseTextJP'] = base_jp
row['BaseTextJP_Source'] = base_src
row['BaseTextJP_Line'] = base_line
row['NewTextJP'] = new_jp
row['NewTextJP_Source'] = new_src
row['NewTextJP_Line'] = new_line
out_rows.append(row)
target_path = output_path or csv_path
# タブ区切りの場合は拡張子を .tsv に変更(.csv のままにしたい場合は出力先で明示)
if delimiter == '\t' and target_path.lower().endswith('.csv'):
target_path = target_path[:-4] + '.tsv'
tmp_path = target_path + '.tmp'
with open(tmp_path, 'w', encoding=output_encoding, newline='') as f:
quoting = csv.QUOTE_ALL if quote_all else csv.QUOTE_MINIMAL
writer = csv.DictWriter(
f,
fieldnames=fieldnames,
extrasaction='ignore',
delimiter=delimiter,
quoting=quoting,
lineterminator='\r\n',
doublequote=True,
escapechar='\\',
)
writer.writeheader()
writer.writerows(out_rows)
try:
shutil.move(tmp_path, target_path)
print(f"Updated CSV with JP columns: {target_path}")
except Exception as e:
# If caller wanted specific output path, try a fallback in same directory
fallback = target_path + '.with_jp.csv'
shutil.move(tmp_path, fallback)
print(f"[WARN] Could not overwrite original. Wrote: {fallback} ({e})")
def process_batch(
fojp_xml: str,
csv_paths: List[str],
include_dirs: bool,
output_dir: Optional[str],
output_encoding: str = 'utf-8-sig',
delimiter: str = ',',
quote_all: bool = True,
) -> None:
print(f"Building English->Japanese map from {fojp_xml}")
mapping = build_en_to_jp_map(fojp_xml, include_dirs=include_dirs)
for csv_path in csv_paths:
out_path = None
if output_dir:
os.makedirs(output_dir, exist_ok=True)
out_path = os.path.join(output_dir, os.path.basename(csv_path))
augment_csv(
csv_path,
mapping,
output_path=out_path,
output_encoding=output_encoding,
delimiter=delimiter,
quote_all=quote_all,
)
def open_gui() -> None:
if tk is None:
print("tkinter is not available in this Python environment.")
return
root = tk.Tk()
root.title("TTW日本語列追加ツール")
root.geometry("900x600")
# Notebook (tabs)
notebook = ttk.Notebook(root)
tab_convert = ttk.Frame(notebook)
tab_help = ttk.Frame(notebook)
notebook.add(tab_convert, text="変換")
notebook.add(tab_help, text="説明")
notebook.pack(fill='both', expand=True)
# Variables
fojp_var = tk.StringVar(value="")
outdir_var = tk.StringVar(value="")
include_dirs_var = tk.BooleanVar(value=False)
# Layout
pad = {'padx': 8, 'pady': 6}
frm_top = ttk.Frame(tab_convert)
frm_top.pack(fill='x', **pad)
# fojp.xml selector
ttk.Label(frm_top, text="fojp.xml").grid(row=0, column=0, sticky='w')
ent_xml = ttk.Entry(frm_top, textvariable=fojp_var)
ent_xml.grid(row=0, column=1, sticky='ew', **pad)
btn_xml = ttk.Button(frm_top, text="参照...", command=lambda: fojp_var.set(filedialog.askopenfilename(initialdir=os.getcwd(), title='fojp.xml を選択', filetypes=[('XML', '*.xml'), ('すべて', '*.*')]) or fojp_var.get()))
btn_xml.grid(row=0, column=2, sticky='w')
frm_top.columnconfigure(1, weight=1)
# Output dir selector
ttk.Label(frm_top, text="出力フォルダ(任意)").grid(row=1, column=0, sticky='w')
ent_out = ttk.Entry(frm_top, textvariable=outdir_var)
ent_out.grid(row=1, column=1, sticky='ew', **pad)
btn_out = ttk.Button(frm_top, text="参照...", command=lambda: outdir_var.set(filedialog.askdirectory(initialdir=os.getcwd(), title='出力フォルダを選択') or outdir_var.get()))
btn_out.grid(row=1, column=2, sticky='w')
# Include dirs checkbox
chk_dirs = ttk.Checkbutton(frm_top, text="辞書ディレクトリも含める", variable=include_dirs_var)
chk_dirs.grid(row=2, column=1, sticky='w', **pad)
# 出力設定
frm_opts = ttk.LabelFrame(tab_convert, text="出力設定")
frm_opts.pack(fill='x', **pad)
ttk.Label(frm_opts, text="エンコード").grid(row=0, column=0, sticky='w')
enc_var = tk.StringVar(value='utf-8-sig')
enc_combo = ttk.Combobox(frm_opts, textvariable=enc_var, state='readonly', values=['utf-8-sig', 'utf-8', 'cp932'])
enc_combo.grid(row=0, column=1, sticky='w', **pad)
ttk.Label(frm_opts, text="区切り").grid(row=0, column=2, sticky='w')
delim_var = tk.StringVar(value=',')
delim_combo = ttk.Combobox(frm_opts, textvariable=delim_var, state='readonly', values=[',', '\t'])
delim_combo.grid(row=0, column=3, sticky='w', **pad)
quote_all_var = tk.BooleanVar(value=True)
ttk.Checkbutton(frm_opts, text="常に引用(Excel推奨)", variable=quote_all_var).grid(row=0, column=4, sticky='w', **pad)
frm_opts.columnconfigure(1, weight=1)
# CSV list frame
frm_csv = ttk.LabelFrame(tab_convert, text="CSV ファイル")
frm_csv.pack(fill='both', expand=True, **pad)
lb = tk.Listbox(frm_csv, selectmode=tk.EXTENDED)
lb.pack(side='left', fill='both', expand=True, padx=6, pady=6)
sb = ttk.Scrollbar(frm_csv, orient='vertical', command=lb.yview)
sb.pack(side='left', fill='y')
lb.configure(yscrollcommand=sb.set)
frm_buttons = ttk.Frame(frm_csv)
frm_buttons.pack(side='left', fill='y', padx=6, pady=6)
def add_csvs():
files = filedialog.askopenfilenames(title='CSV を選択', filetypes=[('CSV', '*.csv'), ('すべて', '*.*')])
for f in files:
if f and f not in lb.get(0, 'end'):
lb.insert('end', f)
def remove_selected():
sel = list(lb.curselection())
for i in reversed(sel):
lb.delete(i)
def clear_all():
lb.delete(0, 'end')
ttk.Button(frm_buttons, text="追加...", command=add_csvs).pack(fill='x', pady=3)
ttk.Button(frm_buttons, text="選択削除", command=remove_selected).pack(fill='x', pady=3)
ttk.Button(frm_buttons, text="クリア", command=clear_all).pack(fill='x', pady=3)
# Log area
frm_log = ttk.LabelFrame(tab_convert, text="ログ")
frm_log.pack(fill='both', expand=True, **pad)
txt = tk.Text(frm_log, height=10)
txt.pack(fill='both', expand=True, padx=6, pady=6)
def log(msg: str):
txt.insert('end', msg + "\n")
txt.see('end')
txt.update_idletasks()
# Run
def run_process():
csvs = list(lb.get(0, 'end'))
if not csvs:
messagebox.showerror('エラー', 'CSV を1つ以上選択してください。')
return
xml_path = fojp_var.get().strip()
if not xml_path or not os.path.isfile(xml_path):
messagebox.showerror('エラー', 'fojp.xml のパスが不正です。')
return
out_dir = outdir_var.get().strip() or None
for w in (btn_xml, btn_out, chk_dirs,):
w.state(['disabled'])
for child in frm_buttons.winfo_children():
child.state(['disabled'])
def worker():
try:
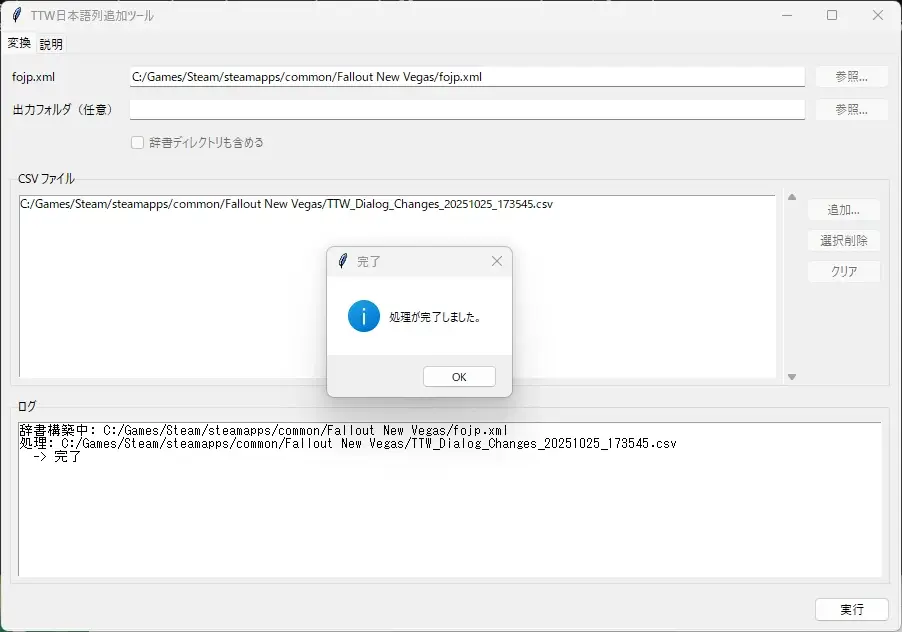
log(f"辞書構築中: {xml_path}")
mapping = build_en_to_jp_map(xml_path, include_dirs=include_dirs_var.get())
for c in csvs:
try:
out_path = None
if out_dir:
os.makedirs(out_dir, exist_ok=True)
out_path = os.path.join(out_dir, os.path.basename(c))
log(f"処理: {c}")
augment_csv(
c,
mapping,
output_path=out_path,
output_encoding=enc_var.get(),
delimiter='\t' if delim_var.get() == '\\t' else delim_var.get(),
quote_all=quote_all_var.get(),
)
log(" -> 完了")
except Exception as e:
log(f"[エラー] {c}: {e}")
messagebox.showinfo('完了', '処理が完了しました。')
except Exception as e:
messagebox.showerror('エラー', str(e))
finally:
for w in (btn_xml, btn_out, chk_dirs,):
w.state(['!disabled'])
for child in frm_buttons.winfo_children():
child.state(['!disabled'])
threading.Thread(target=worker, daemon=True).start()
frm_run = ttk.Frame(tab_convert)
frm_run.pack(fill='x', **pad)
ttk.Button(frm_run, text='実行', command=run_process).pack(side='right')
# 初期状態ではCSVは自動追加しません(ユーザーが参照で選択)
# Help tab content
help_pad = {'padx': 10, 'pady': 8}
frm_help_top = ttk.Frame(tab_help)
frm_help_top.pack(fill='x', **help_pad)
ttk.Label(frm_help_top, text='使い方 / 説明(READMEの内容を表示)').pack(side='left')
def load_help() -> str:
return HELP_TEXT
btn_reload = ttk.Button(frm_help_top, text='再読込', command=lambda: (txt_help.delete('1.0', 'end'), txt_help.insert('1.0', load_help())))
btn_reload.pack(side='right')
frm_help_body = ttk.Frame(tab_help)
frm_help_body.pack(fill='both', expand=True, **help_pad)
txt_help = tk.Text(frm_help_body, wrap='word')
scr_help = ttk.Scrollbar(frm_help_body, orient='vertical', command=txt_help.yview)
txt_help.configure(yscrollcommand=scr_help.set)
txt_help.pack(side='left', fill='both', expand=True)
scr_help.pack(side='left', fill='y')
# Initial help content
txt_help.insert('1.0', load_help())
root.mainloop()
def main(argv: List[str]) -> int:
parser = argparse.ArgumentParser(description='Augment TTW Dialog Changes CSV with Japanese text and source info from fojp.xml dictionaries.')
parser.add_argument('--fojp', default='fojp.xml', help='Path to fojp.xml (default: fojp.xml in this directory)')
parser.add_argument('--csv', nargs='*', help='CSV files to process (default: the two known TTW CSVs)')
parser.add_argument('--include-dirs', action='store_true', help='Include directory dictionaries too (default: off)')
parser.add_argument('--output-encoding', default='utf-8-sig', choices=['utf-8-sig', 'utf-8', 'cp932'], help='Output file encoding (default: utf-8-sig)')
parser.add_argument('--delimiter', default=',', choices=[',', 'tab'], help="Delimiter: ',' or 'tab' (default: ',')")
parser.add_argument('--quote-all', action='store_true', help='Quote all fields (default: off)')
args = parser.parse_args(argv)
script_dir = os.path.dirname(os.path.abspath(__file__))
fojp_xml = args.fojp
if not os.path.isabs(fojp_xml):
fojp_xml = os.path.join(script_dir, fojp_xml)
print(f"Building English→Japanese map from {fojp_xml}")
mapping = build_en_to_jp_map(fojp_xml, include_dirs=args.include_dirs)
if args.csv and len(args.csv) > 0:
csv_paths = [p if os.path.isabs(p) else os.path.join(script_dir, p) for p in args.csv]
else:
csv_paths = [
os.path.join(script_dir, 'TTW_Dialog_Changes_20251025_173545.csv'),
os.path.join(script_dir, 'FNVEdit 4.1.5f', 'TTW_Dialog_Changes_20251025_173545.csv'),
]
delim = '\t' if args.delimiter == 'tab' else ','
for csv_path in csv_paths:
augment_csv(
csv_path,
mapping,
output_encoding=args.output_encoding,
delimiter=delim,
quote_all=args.quote_all,
)
print('Done.')
return 0
if __name__ == '__main__':
# If no arguments or --gui specified, open GUI; otherwise run CLI
if len(sys.argv) == 1 or '--gui' in sys.argv[1:]:
ensure_tkinter_available()
open_gui()
else:
raise SystemExit(main(sys.argv[1:]))
使いやすいようにGUIを用意した。csv、fojp.xml、出力先を指定すれば、先程のcsvに日本語化データを追加することができる。
そうすると、どうなるかと言うと…
- esmで変更されたダイアログの
- 変更前のテキスト
- 変更前のテキストの日本語化
- 変更後のテキスト
- 変更後のテキストの日本語化
上記をとりあえず一発で全部確認できる。
さらにその日本語化のデータは、どのNVJPのファイルを用いて翻訳されたのかを、ファイルパスで見れるようにもしてある。
例:
基本は全部一行に納まっているが、ここに掲載すると見づらいので、列を分けて説明します。
まずベーステキスト(esmで変更される前)のデータは下記のように見れる。
| ベーステキスト | ベーステキストの翻訳 | 翻訳に使用されたFOJPのファイル | 行数 |
| You’ll be wanting the reward now, won’t you. I suppose you’ve earned it. | 報酬が欲しいんだな、だろ。それだけの仕事はしたよな | NVJP/ikkatsu/FOtrans_FO3DIAL_jp.txt | 16226 |
ほんとは話者とかFormIDとかの列もあるが、ここでは省略
つぎに、esmで変更された後のデータが続く。
説明の便宜上、変更点をハイライトしてみた。下記テキストでは、単に”?”が追加されただけのようである。
| 変更後のテキスト | 変更後のテキストの翻訳 | 翻訳に使用されたFOJPのファイル | 行数 |
| You’ll be wanting the reward now, won’t you? I suppose you’ve earned it. | 報酬が欲しいんだな、だろ。それだけの仕事はしたよな | NVJP/ttw333b/TTW333b_ja.txt | 20617 |
そして音声ファイルに関する情報が続く。
| ベースのVoiceファイル | 変更後のVoiceファイル |
| ms12_greeting_000031da_1.ogg | ms12_ms12gustavoghoulsdead_000031da_1.ogg |
これで、まずベースのセリフの英語版がナニで、日本語版がナニか。そして変更後はどうなっているかがわかる。
また音声ファイルもどれがどれだか把握できる。
こんな感じで、「ダイアログ編集されてるけど、これは別に日本語音声をつくる必要はないな…」みたいな判断をするために使う。
あと副次的に、esmで変更されたバニラのダイアログの日本語化補助にもなる。
で、このツールでなにができるかというと
各ダイアログやセリフの情報の”把握”ができる!!!
これが何に使えるかとかは、知らない!!!
TTWの日本語音声を最新版に対応させたり、不備がありそうなのでイチから作り直すときに使う目的で作ったが、その作業が面倒くさすぎて、ツールだけ作って力尽きたというわけです。

最新版の日本語音声が配布されてると、本当に思ったんですか?
甘えるんじゃない!自分でやるんだ!








コメント