完成版の配布ページはこちら
アーカイブ
前回は、YAMPTを使ったリバースエンジニアリングと、辞書(Glossary)の作成、そしてClaude Haikuを使ったベース翻訳の作成までをやった。
今回は、いよいよ本丸であるINFO(会話テキスト)の翻訳における「コンテキスト問題」と、その技術的解決について書いていこうと思う。
まず3,000行くらい翻訳してみて、プロンプトの改善、辞書マスターによる表記ゆれ対応、翻訳精度の向上を確認できたので、仮翻訳に移ることにした。
その前に、このINFO.tsvにおける最大の問題点を解決しないといけなかった。
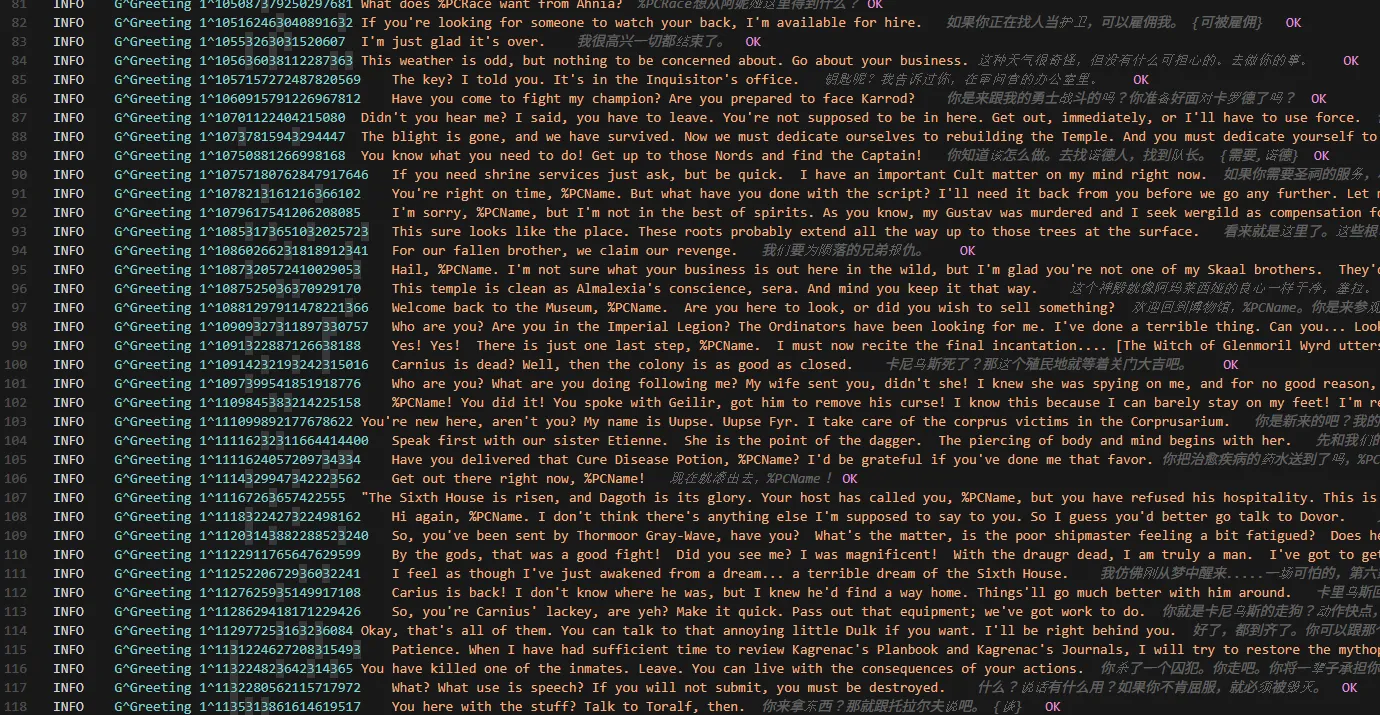
誰が喋っているのかが一切わからない
翻訳自体は進んだが、INFO(会話データ)には致命的な欠点があった。
現状だと、keyによって何が喋ってるか(衛兵なのか、ネレヴァリンなのか)は、ざっくりだが理解できていたが、
- 誰が(NPC名)
- どこで(CELL)
- どういう状況で(シチュエーションやクエスト進行度)
などの情報が無かったので、これらを.tsvに追加してAIに渡してやらないと、訳質に限界があった。
そこで、PythonでESMバイナリを直接パースし、コンテキスト情報を抽出することにした。
誰が、とか、どこで、とか、そういった情報を会話文のデータから取り出そうというわけだ。
ESMバイナリ解析
既存のツール(tes3convなど)では必要な情報が欠落するため、Pythonの struct モジュールと construct ライブラリを使ってバイナリを直接解析した。
INFOレコードには DATA や ONAM(話者)といったサブレコードが含まれている。
これらを解析することで、以下の情報が抽出できた。
| 抽出した情報 | 具体例 |
|---|---|
| 話者 (ONAM) | 衛兵 (guard_hlaalu) |
| 場所 (CELL) | バルモラ |
| クエストID | A1_1_FindSpymaster |
これで「特定NPCのセリフだけ見て翻訳」「ガード汎用だけ口調を統一」みたいな実務ができるようになった。
これをプロンプトに注入することで、「噂を聞いたか?」を「最近の噂を聞いたか?(衛兵口調)」にするなど、細かい状況や話者のニュアンスを反映させることができるようになった。
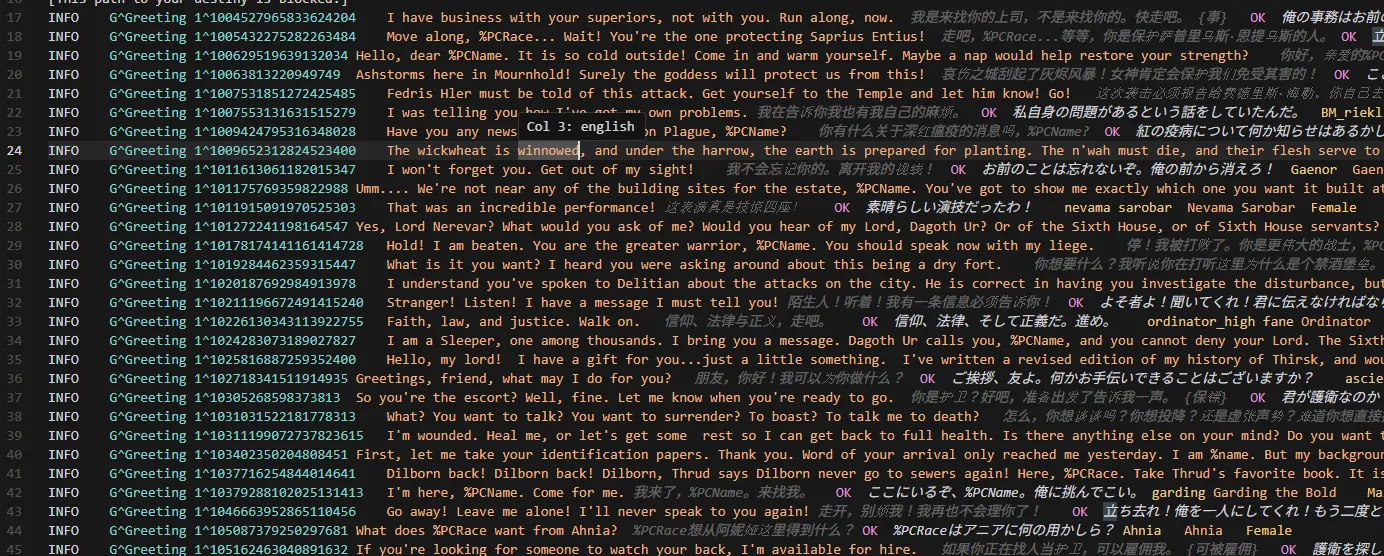
しかしあとになって、男女の情報に不整合があって、性別の固定をしていたせいで、数千行の翻訳をやり直す羽目になってしまった。
基本的にNPCは、トピックに基づいて話すセリフは固定なのに、男性だったり女性だったりする。
ところが翻訳側で「male」(男)と固定してしまっていたせいて、女性のNPCが急に「俺は~」と言い出したりする場面が発生していた。
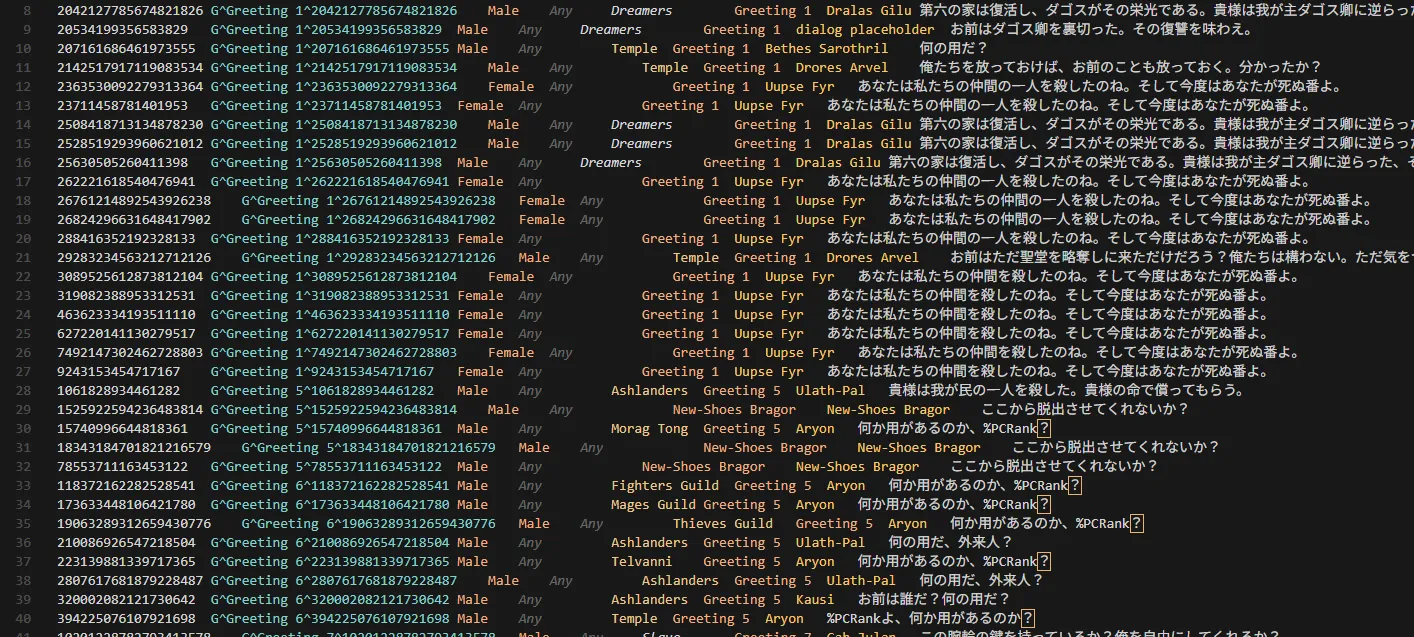
これは、抽出スクリプトを作るときに、話者でなく会話を持っているNPCのリストの最初だけを参照して性別を判定していたことが原因だった。
この問題が起きてからは、まずNPCの性別マスタを作り、そのうえで会話を持っているすべてのNPCを解析して差分を取ることで、Both(男女共用)のセリフがどれだかわかる判定をつくった。
TES何年プレイしてんだよ、当たり前だろ!と言われそうなミスだった。
ESP生成スクリプトの開発
そんなこんなで、とりあえず、なんとか翻訳データは揃った!(仮だけど)
あとはこれをESP(パッチファイル)として書き出すだけだったが、ここからが本当の地獄だった。
最初の試み — 完全な失敗
最初はシンプルに、中華版と同じ構造のパッチESPを生成しようとした。
中国語版をベースに作ったので、中国語版と同じesp構造にしておけばいいだろうと言う安直な判断。
結果: バイナリレコードヘッダーの逆スキャンロジックが壊れており、生成されたESPが構造的エラーを含み、ゲームが読み込めない。
2バイトの罠
ならば・・・と、根本的に書き直し、2パス処理に変更した。
しかし、またしてもESPが壊れる。
ESPをバイナリダンプして確認すると、恐ろしいことが起きていた。
INAM size=21 のはずが、データが \x00\x003064...原因は、TES3フォーマットのサブレコードサイズを4バイト(Integer)ではなく2バイト(Short)だと勘違いして進めていたせいだった。
原因の調査に半日かかった。
# 間違い
struct.pack('<I', size) # 4バイトで書き込んでいた
# 正解
struct.pack('<H', size) # 2バイトだった!たった2バイトのズレ。しかし、これがファイル全体のアドレスを狂わせていた。
「レコード構造なんて大体一緒だろw」という思い込みが招いた恥ずかしいミスだ。
辞書キーの不一致
問題を直し、ようやくESPが生成できた。
しかし、ゲーム内でINFO(対話テキスト)が全部英語のままだった。
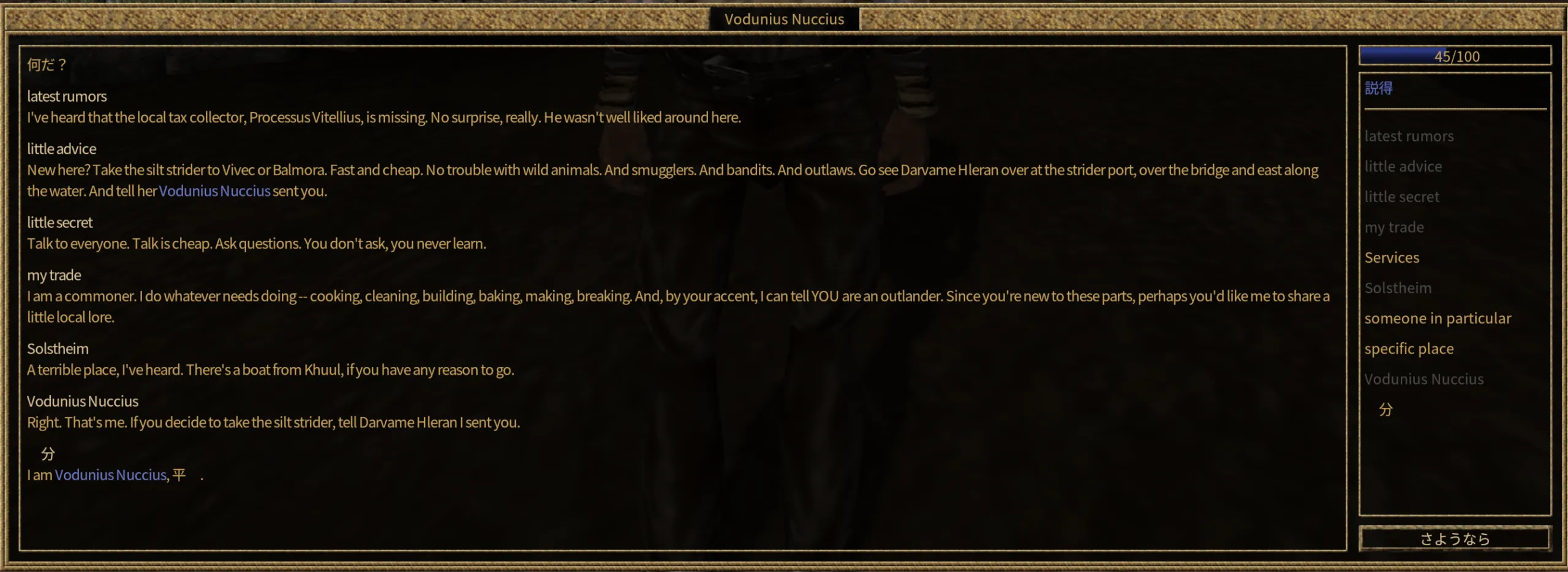
調べてみると、翻訳辞書のキー(INAM値)が中華版ESPのINAMと一致していなかった。
翻訳ツールが使った英語ESMと、実際にゲームで使う中華版ESPでは、同じ対話でもINAM値が異なっていた。
影響範囲は約12,543個。ひぃぃい、
これを解決するために、以下の3段階のマッピングを実装した。
- 英語ESM全体からINAMマッピングを構築
- 中華版ESPとの相互参照で正確な対応関係を復元
- 日本語翻訳辞書を正しいキーで再構築
このへんで、mdに各一時バッチの設計をまとめていなかったせいで、頭がかなりこんがらがってしまい、ほとんど手動という悲しいやり方になった。
とりあえず、これでようやく、ゲーム内で日本語テキストが表示された。
「最初のクエストが進まない」
ゲーム起動!
ニューゲーム起動!
・・・しかし始めてみると、最初のシーンでジウブ(NPC)が話しかけてこない。
・・・ずっとお互い無言のまま、船はつかない。
原因を探ると、スクリプト内のテキストが中国語(GBKエンコード)のままなのに気づいた。
OpenMWをUTF-8モードで動かしているため、GBKのテキストを読み込んだ瞬間にパースエラーを起こし、スクリプトが停止していた。
なので、スクリプトに含まれる Say や MessageBox コマンド内のテキスト("You're finally awake..."など)を検出し、日本語に翻訳してUTF-8で書き直すことで、ようやくジウブが喋りだした。
おかえり、ジウブ。

アーカイブ



コメント