完成版の配布ページはこちら
アーカイブ
はじめに
The Elder Scrolls III: Morrowindは、2002年にリリースされた名作RPGです。日本語版は公式には存在しません。
今回、OpenMWの中華版フォーク(中国語対応済み)をベースに、完全な日本語版Morrowindを実現するプロジェクトに取り組んだ。
本記事は、その全行程を記録したものだ。
トピックシステムの壁
まず簡単にMorrowindの「トピック」というものの仕様について解説する。
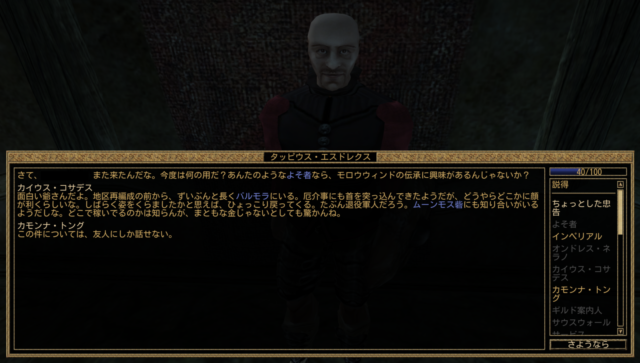
Morrowindの会話システムは、Oblivion以降のTESシリーズとは根本的に異なる設計思想で作られている。
- NPCに話しかけると、画面左側に「トピック一覧」がリスト形式で表示される
- プレイヤーはその中から聞きたい項目をクリックして選択する
- NPCは選択されたトピックに対して、テキストで応答を返すという形式
- 音声はほとんど実装されておらず、会話の大部分はテキストベースで進行する
- これにより、膨大な量のダイアログを収録することが可能になっている
Morrowindのトピック最大の特徴は、一度アンロックしたトピックはすべてのNPCに対して使用できるという点。
- たとえば、バルモラという街でNPCから「ネレヴァリン」というトピックを教えてもらったとする
- 以降、このトピックはプレイヤーのトピック一覧に追加され、ヴァーデンフェル全土のあらゆるNPCに対して「ネレヴァリンについて教えてください」と尋ねることができるようになる
- ただし、すべてのNPCがすべてのトピックに応答できるわけではない
- 該当するトピックへの応答データを持っていないNPCの場合、そのトピックはそもそも一覧に表示されない
- ただ、勢力や思想が異なるキャラクターは、同じトピックに対しても異なる返答をもつ場合がある
Morrowindの日本語化では、この「トピック」の仕様が、日本語化を遮る大きな壁になっていた。
従来の日本語化の問題点
既存の日本語化プロジェクトでは、以下のアプローチが取られている。
- 表示される文章(INFO)だけを訳す
- システムが参照する検索キー(DIALトピックやCELL名)は英語のまま残す
Morrowindには、特定のトピック文字列の出現をトリガーとしてクエストが進行するという、やっかいな仕様がある。
トピック名を日本語に翻訳してしまうと、クエストの進行フラグが正しく立たなくなる可能性がある。逆に言えば、トピック名を英語のままにしておけば、文中に英語が大量に混ざるものの、バグは起きにくいということでもあった。
そもそもMorrowindのオリジナルエンジンは、日本語などの2バイト文字の表示に対応していない。そのため日本語化自体がかなりの力技で、外部ツールでフォントを差し替えたり描画処理に手を加えたりと、導入にはそれなりの技術的知識が必要だった。
また、様々な有志が作ったバラバラの日本語化MODを組み合わせる必要があり、導入手順も非常に複雑だった。Morrowindはとにかくテキスト量が膨大なゲームなので、有志翻訳のやり方や範囲もバラバラになりがちで、統一感のある日本語環境を作るのが難しい状態が長く続いていた。
OpenMWの登場により希望が出てきた
OpenMWとは
OpenMWは、Morrowindのゲームエンジンをオープンソースで完全に再実装するプロジェクトだ。オリジナルのMorrowindエンジン(Gamebryo)が抱えていた技術的な制約や不具合を解消しつつ、オリジナルのゲームデータ(.esmファイルや.bsaアーカイブ)をそのまま読み込んで動作させられる。
そしてなにより、OpenMWではフォント設定がより柔軟になっており、日本語環境の構築に大きな希望があった。
dwing4g/openmwを使う
dwing4g/openmw は、ただのOpenMWではなく、中国語(マルチバイト文字)を正しく表示・入力・制御するためにエンジン自体を改造したカスタムビルド。
もともとのOpenMWはマルチバイト非対応だったが、この中国語Fork版を改良することで、日本語表示対応させた日本語版OpenMWを作ろう、というのが今回のプロジェクトの根幹となる
簡単に言うと、
- オリジナルのMorrowindのエンジンは使いづらい
- 画期的なOpenMWエンジンが登場したが、日本語非対応
- それのFork版であるdwing4g/openmwが出たが、中国語専用
- 2byte文字(日本語や中国語)に対応してるので、これを改造することで日本語を表示させられるのでは?
という計画。
中国語版espという「お手本」
じつは、中国語版のMorrowindは、すでに完全な翻訳が完了していてNexusで配布されている。
Unofficial Chinese Localisation for Morrowind by Pack Rat EN-CN
この中国語版の翻訳MODでは、NPC名やトピックを含む、すべての文字が中国語として実装されている。つまり何らかの方法でトピックのリンク問題を解決し、完全な中国語化に成功しているということ。
まずはこいつをリバースエンジニアリングして、日本語でも同じことが可能か調べていくことにした。
YAMPTを使ってリバースエンジニアリングする
YAMPT(ローカライズツール)で翻訳されたespとオリジナルの英語esmを比較して、どこをどう翻訳しているかを見てみることに。
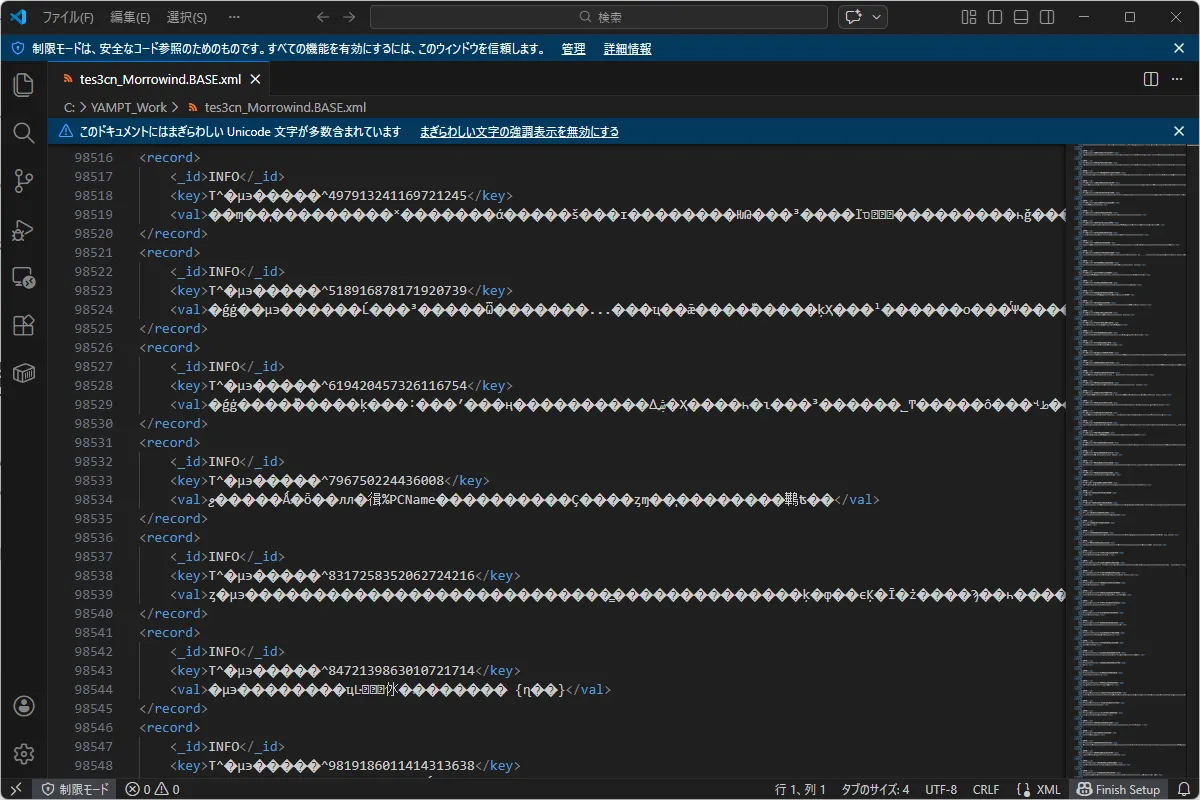
- みていくと、中国語版ではespをGB2312(中国語文字エンコード)で翻訳している様子
- OpenMW自体は既にUTF-8の読み込みに対応している
中国語版と同じように言語コードを日本仕様に合わせて実装することもできたが、OpenMWはUTF-8を読み込める仕様になっていたので、ここは素直にUTF-8のまま作業していく方針にした。
恐ろしい中国語版の翻訳作業量
中華版のespの翻訳をUTF-8に戻して眺めていると、とんでもないことに気づいた。
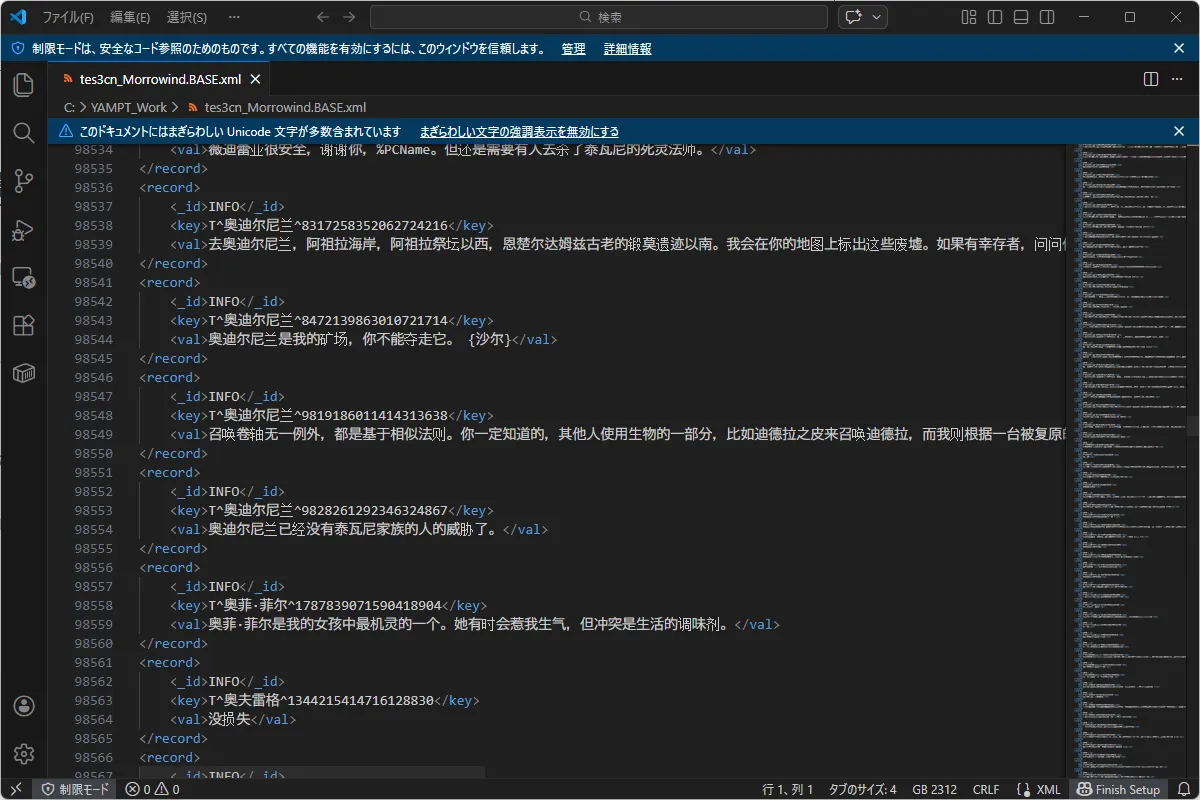
あろうことか、中国版は「完全翻訳(Hard Translation)」を目指すあまり、ゲームの内部で参照キーとして使われる「トピック名(DIAL)」全体を中国語に書き換えてしまっていた。
- つまりこの段階で、中国版のデータ構造は改造されすぎていて、ただ翻訳箇所を抽出しても意味がないことがわかった。
- もしこのXMLを日本語に翻訳して注入しても、英語版のゲーム側には「中国語のキー」なんて存在しないため、マッチングせず一行も翻訳が反映されない
どうすればいいか?
中国の同志たちが成し遂げたなら、我々にもできるはずだ!
トピック(DIAL)も、ダイアログも、すべて日本語化した「完全日本語版(Full Translation)」を目指す。
まず、これを成し遂げるためにやるべきことを考える。
辞書(Glossary)の作成
作業計画はこうだ。
- 辞書(Glossary)を作る
まずトピックだけを抽出して翻訳し、「英日対訳リスト」を作る。
(例:advancement = 昇進, background = 生い立ち…) - さらに辞書を作る
FNAMやRNAM、DIALも抽出し、さらに辞書を拡充させていく - 本文を翻訳する
INFO(会話)やBNAM(プレイヤーの選択肢)を、作成した対訳リストに基づいて翻訳する
簡単そうだ!
とにかく、何ができるか考えてみよう。
実データを見ながら、日本語化の障害を調べていくことにした。
CELL名は翻訳できない?
.epsの中身を見ていると、中国語版はCELL名の1,440件のうち、わずか17件しか翻訳していない(98.8%がMISSING)。
これは、場所名を翻訳すると、ゲームが進行不能になる(詰む)確率が極めて高いから、ということらしい。
なぜ「トピック(DIAL)」は翻訳していいのに、「場所(CELL)」はダメなのか?
スクリプトが「場所の名前」を文字で指定しているから
これが最大の理由。
Morrowindのプログラム(スクリプト)の中には、以下のような命令がたくさん書かれている。
命令例:
Player->PositionCell 0, 0, 0, 0, “Balmora, Guild of Mages”
(プレイヤーを「Balmora, Guild of Mages」という名前のセルに移動させろ)
もし、CELLデータを翻訳して、場所の名前を 「バルモラ、魔術師ギルド」 に書き換えたとする。
- ゲーム内
場所の名前は「バルモラ、魔術師ギルド」(日本語)になった - スクリプト
スクリプトは英語で書かれているままなので、「Balmora, Guild of Mages」を探せ、と命令する - 結果
「そんな場所(英語名)は見つからない」 となり、テレポートが発動しない
クエストで飛ばされるはずのイベントが起きず、ゲームが進行不能になる。
中国語版の解決策: .celファイル
だが、中国語版ではCELL名も含めた「完全翻訳」を成し遂げている。
調べていくと、中国語版はMorrowind.celを使用してセル名を翻訳していることがわかった。
中国語MODのCELL翻訳の仕組み
| 翻訳対象 | 方法 |
|---|---|
| セル名(場所名)1,423箇所 | .celファイル で翻訳 → ESPでは全部MISSING |
| FNAM, INFO, TEXT, BNAM等 | ESP で翻訳 |
CELL_glossary.tsvの 1,423件のMISSINGが、.celの1,423件と完全に一致(カバー率100%)- 中国語ESPのCELLレコードは1,226件中1,216件がMISSING
- つまり 意図的に
.espではセル名を翻訳せず、.celに任せている
つまり日本語版でもMorrowind.celを作る必要がある。
TSVで差分を取る
問題点がわかったので、各.espの中身(オリジナルの英語版と、完成している中国語版)を比較して、キーの判定や翻訳する箇所としない箇所の差分(diff)を取得し、TSV化してまとめた。
つまり、
- どのキーの
- どの文章を
- どこだけ
- どのように
翻訳しているか、というのを機械的にまとめて、作業しやすくしたわけだ。
これは完成されている中国語版というお手本があるからできることであり、イチからこれを作成した中国の有志たちには頭が上がりません。
これで、あとは原文と中国語版を参考に、機械的に日本語化作業ができる。
Claude Haikuで翻訳を進める
AIによる大量翻訳
当時は無かったが、いまはAIがある。
英語→日本語の翻訳では、圧倒的にClaude Haikuが強い。APIのコストはかかるが、30,000行強あるMorrowindのダイアログすべてを手動で翻訳してたら、数カ月はかかってしまう。
なので、Pythonでバッチ翻訳スクリプトを作って、Morrowindでよく使われる用語などをプロンプトで渡しつつ、機械的に翻訳をさせることにした。
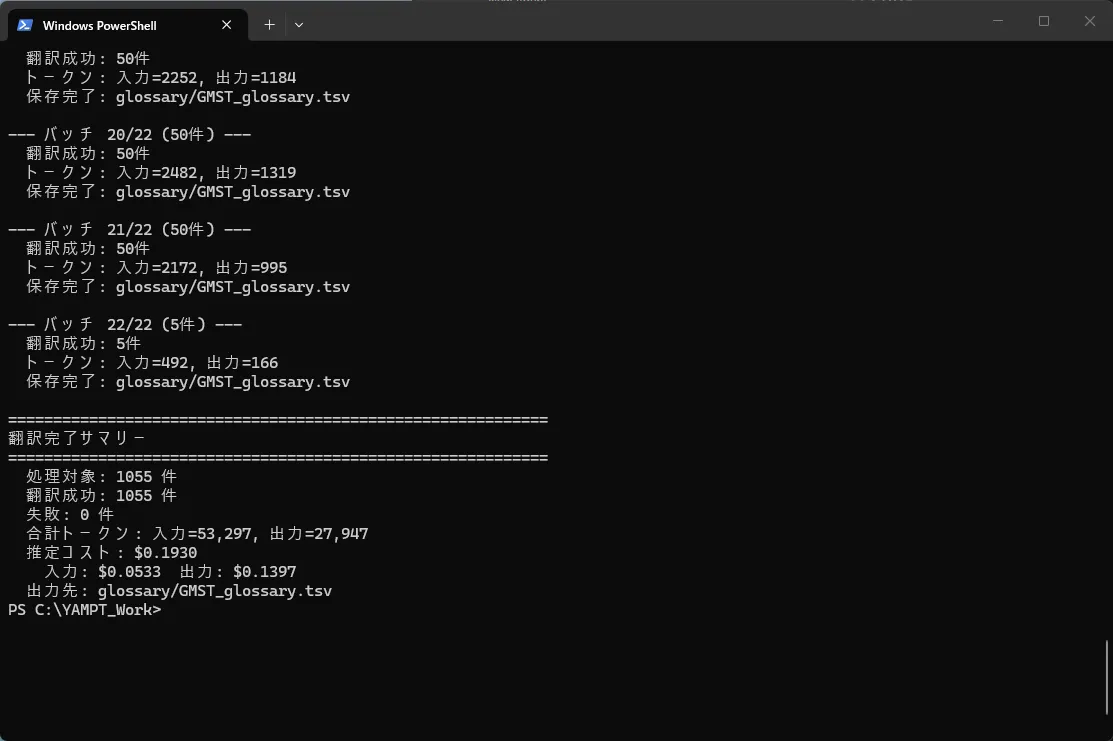
1,000件程度で0.19ドル(約30円)なので、基本的にはこれで下地をつくっていくことにした。
最初のプロンプト(失敗)
最初のプロンプトはシンプルだった:
あなたはゲーム翻訳者です。以下の英語テキストを日本語に翻訳してください。
中国語の参考訳も提供しますが、あくまで参考です。
[英語テキスト]
[中国語参考訳]
結果は散々だった。
精度の問題
| カテゴリ | 件数 | 深刻度 | 具体例 |
|---|---|---|---|
| 用語集違反 | ~17箇所 | 高 | 「Enchant」を「エンチャント」と訳すべきところを「付呪」「附魔」など |
| 訳語の混在 | ~30箇所+ | 高 | 同じ単語が「魔術師」「メイジ」「魔法使い」とバラバラ |
| 中国語残留 | ~25箇所 | 高 | 「附魔」「狼人」「尸化病」がそのまま |
| 文法・表現 | ~5箇所 | 中 | 不自然な敬語、口調の不統一 |
AIが中国語参照訳に引きずられる問題が深刻だった。
AIは「参考」と言われても、目の前にある中国語をそのまま使ってしまう傾向があった。
まぁこれは、どちらかというとClaude Haikuのせいだが・・・
プロンプト改善 第1弾:用語集の追加
まず、用語集を明示的に渡すようにした:
必須用語集(厳守)
英語 日本語 Enchant 付呪 Alchemy 錬金術 Conjuration 召喚 禁止事項
- 中国語をそのまま使わないこと
- 用語集にある単語は必ず指定の訳語を使うこと
これで用語集違反は減ったが、コストが3倍に増えた。入力トークンが増えたからだ。

プロンプト改善 第2弾:md形式への変更
Twitterで「AIにわたすプロンプトはMarkdown形式がいいよ」と聞いたので、プロンプト全体をMarkdown形式に構造化した。
# 翻訳タスク ## コンテキスト - ゲーム: The Elder Scrolls III: Morrowind - ジャンル: ファンタジーRPG - 時代設定: 中世風 ## 翻訳ルール 1. 用語集の訳語を厳守 2. 中国語参考訳は参考のみ、日本語に直接使用禁止 3. ファンタジー世界観に合った文体 ## 用語集 [表形式で用語を列挙] ## 翻訳対象 [テキスト]
構造化したことで、AIの理解度が向上し、用語集違反がさらに減った。
プロンプト改善 第3弾:多段階処理
それでも精度が足りなかったので、多段階処理を導入した:
- 第1段階(Haiku): 素の翻訳を生成
- 第2段階(スクリプト): 用語集と校正ルールで機械的に修正
- 第3段階(Opus): 変更ログを見せてチェック・最終調整
この多段階処理により、精度が大幅に向上した。
DIALラインは2,098行で、100円くらいだった。
辞書マスターの整備をした
翻訳が進むにつれ、表記ゆれが問題になってきた。
同じ単語でも、翻訳者(AI)の気分で訳語が変わる。
| 英語 | 訳語A | 訳語B | 訳語C |
|---|---|---|---|
| Mages Guild | 魔術師ギルド | メイジギルド | 魔法使いギルド |
| Fighters Guild | 戦士ギルド | ファイターギルド | 闘士ギルド |
| Thieves Guild | 盗賊ギルド | シーフギルド | 泥棒ギルド |
特に問題になったのが素材名だった。
| 英語 | 中国語 | 初期の日本語訳 | 統一後 |
|---|---|---|---|
| Glass | 碧水晶 | ガラス / 碧水晶 / グラス | ガラス |
| Ebony | 黑檀 | 黒檀 / エボニー / 黒壇木 | 黒檀 |
| Boiled Leather | 煮沸革 | 煮沸革 / ボイルドレザー | 硬化革 |
| Daedric | 魔神 | デイドリック / 魔神 | デイドラ |
「碧水晶」は中国語訳がそのまま残ってしまった例。「黒壇木」は「黒檀」の誤記。
これを防ぐため、辞書マスターを作成した。
全ての固有名詞、組織名、地名、アイテム名を一覧化し、「この単語はこの訳語を使う」と決めた。
これをプロンプトに注入することで、表記ゆれを一気に抑えることができた。
アーカイブ



コメント